
трансляция — Жилой комплекс КМ Анкудиновский парк
Оставьте телефон, мы перезвоним вам в ближайшее время и расскажем, как получить выгодную ипотеку на квартиру мечты
[1] Настоящим даю согласие на обработку моих вышеуказанных персональных данных ООО «СЗ «КМ Парламент» (603093, Россия, Нижний Новгород, улица Родионова, дом 192, корпус 3) (далее – Оператор)
с целями: обработки моего запроса, направленного через сайт www.km-ankudinovka.ru, и коммуникации со мной в целях, связанных с обработкой и выполнением моего запроса с помощью различных средств связи, а именно посредством:
интернет; сообщений на адрес электронной почты; коротких текстовых сообщений (SMS) и мультимедийных сообщений (MMS) на номер телефона; а также посредством использования информационно-коммуникационных сервисов, таких как Viber, WhatsApp и тому подобных; телефонных звонков.
Я разрешаю совершать со своими персональными данными следующие действия: сбор, систематизацию, накопление, хранение (в электронном виде и на бумажном носителе), уточнение (обновление, изменение), использование, распространение (в том числе передачу) моих персональных данных третьим лицам, с которыми у Оператора имеются действующие договоры, в рамках которых Оператор поручает обработку персональных данных в вышеуказанных целях, включая трансграничную передачу персональных данных, обезличивание, блокирование, уничтожение, с использованием средств автоматизации и без использования таких средств.
Настоящее согласие на обработку моих персональных данных действует до момента выполнения моего запроса и может быть отозвано мною ранее в соответствии со статьей 9 Федерального закона от 27.07.2006 года №152-ФЗ «О персональных данных» посредством направления соответствующего письменного заявления по почтовому адресу Оператора, указанного в настоящем согласии, или в электронной форме посредством направления запроса на электронный адрес hotline@karkasmonolit.
ООО «СЗ «КМ Парламент» ведет деятельность на территории Российской Федерации в соответствии с законодательством Российской Федерации. Предлагаемые Оператором в заявленных в настоящем согласии целях товары/услуги/работы доступны к получению на территории Российской Федерации. Мониторинг потребительского поведения лиц, находящихся за пределами Российской Федерации, Оператором не ведется.
[2] Настоящим даю согласие на обработку моих вышеуказанных персональных данных ООО «СЗ «КМ Парламент» (603093, Россия, Нижний Новгород, улица Родионова, дом 192, корпус 3) (далее – Оператор)
с целями: учета предоставленной информации в базах данных; проведения статистических исследований, а также исследований, направленных на улучшение качества продукции и услуг; проведения маркетинговых программ, в том числе, для продвижения товаров, работ, услуг на рынке; информирования меня о новых товарах и услугах Оператора и партнеров Операторов (например, посредством отправки журналов, отправки приглашений на презентации продуктов, сообщений о технических нововведениях, предстоящих работах по сервисному обслуживанию, условиях покупки нового автомобиля и т.
интернет; сообщений на адрес электронной почты; коротких текстовых сообщений (SMS) и мультимедийных сообщений (MMS) на номер телефона; а также посредством использования информационно-коммуникационных сервисов, таких как Viber, WhatsApp и тому подобных; телефонных звонков.
Я разрешаю совершать со своими персональными данными следующие действия: сбор, систематизацию, накопление, хранение (в электронном виде и на бумажном носителе), уточнение (обновление, изменение), использование, распространение (в том числе передачу) моих персональных данных третьим лицам, с которыми у Оператора имеются действующие договоры, в рамках которых Оператор поручает обработку персональных данных в вышеуказанных целях, включая трансграничную передачу персональных данных, обезличивание, блокирование, уничтожение, с использованием средств автоматизации и без использования таких средств.
В целях проведения маркетинговых программ, в том числе для продвижения товаров, работ и услуг, ООО «СЗ «КМ Парламент» может заключать соответствующие Договоры с третьими лицами относительно условий предоставления мне финансовых услуг. Настоящим я даю свое согласие на получение информации о предлагаемых такими третьими лицами финансовых услугах. Указанная информация может быть доведена до моего сведения как ООО «СЗ «КМ Парламент», так и самими компаниями-партнерами ООО «СЗ «КМ Парламент», предлагающими такие финансовые услуги.
Настоящим я даю свое согласие на получение информации о предлагаемых такими третьими лицами финансовых услугах. Указанная информация может быть доведена до моего сведения как ООО «СЗ «КМ Парламент», так и самими компаниями-партнерами ООО «СЗ «КМ Парламент», предлагающими такие финансовые услуги.
Настоящее согласие на обработку моих персональных данных действует до момента его отзыва.
Настоящее согласие может быть отозвано мною в любое время в соответствии со статьей 9 Федерального закона от 27.07.2006 года №152-ФЗ «О персональных данных» посредством направления соответствующего письменного заявления по почтовому адресу Оператора, указанного в настоящем согласии, или в электронной форме посредством направления запроса на электронный адрес [email protected].
ООО «СЗ «КМ Парламент» ведет деятельность на территории Российской Федерации в соответствии с законодательством Российской Федерации. Предлагаемые Оператором в заявленных в настоящем согласии целях товары/услуги/работы доступны к получению на территории Российской Федерации.
Просветительский фонд «Эволюция»
Просветительский фонд «Эволюция»Совет фонда
Борис Штерн
доктор физико-математических наук, главный редактор газеты «Троицкий вариант — Наука», финалист премии «Просветитель»Михаил Гельфанд
доктор биологических наук, член Academia Europaea, заместитель директора ИППИ РАН, профессор «Сколтеха», НИУ ВШЭ и МГУАлександр Марков
доктор биологических наук, лауреат премии «Просветитель»Ася Казанцева
научный журналист, лауреат премии «Просветитель»Борис Долгин
советник ректора НИУ ВШЭАлександр Панчин
кандидат биологических наук, старший научный сотрудник Института проблем передачи информации РАНИрина Левонтина
кандидат филологических наук, ведущий научный сотрудник Института русского языка РАН, финалист премии «Просветитель»Варвара Горностаева
главный редактор издательства CorpusАлександр Дубынин
организатор научных событий, директор фестиваля науки EUREKA!FESTАскольд Иванчик
доктор исторических наук, член-корреспондент РАНВалерий Рубаков
доктор физико-математических наук, академик РАНПётр Талантов
врач, член Комиссии РАН по противодействию фальсификации научных исследований, лауреат премии «Просветитель»Юрий Баевский
организатор научных фестивалей, старший преподаватель нижегородского филиала ВШЭПомогите фонду
Новости фонда
Ваш платеж успешно выполнен
Ваш платеж не прошел
 Просветительский фонд «Эволюция». Все права защищены.
Просветительский фонд «Эволюция». Все права защищены. Безопасность платежей Политика конфиденциальности
Медицинская клиника Асмедика в СПб
Мы рады, что Вы обратились за помощью именно к нам, потому что все, что касается здоровья нам не безразлично. Определенно быть лучшими крайне трудно, но мы стараемся. Сегодня нам удается многое и можно даже сказать, что в некоторых направлениях мы являемся лидерами. Некоторые заболевания ТАК эффективно лечим только мы, поскольку используем самые передовые, безопасные и качественные медицинские технологии.
В нашей Клинике мы гарантируем Вам соблюдение принципов врачебной этики и конфиденциальность полученной информации, а также стараемся, чтобы посещение нашей клиники проходило для Вас в максимально комфортной и доброжелательной обстановке.
Приходите, мы сделаем все, чтобы помочь Вам!
10 причин, которые убеждают вас в том, что «Асмедика» – ваша клиника
1) «Всё в одном».
Что это значит?
Все просто: «Асмедика» – сеть многопрофильных медицинских центров, где вы решаете проблемы со здоровьем комплексно. Поэтому абсолютно все необходимые вам лабораторные исследования (а также вся функциональная диагностика и УЗИ диагностика) проводятся в клинике. Для того чтобы сдать анализы, сделать ЭКГ, сделать УЗИ – то есть, пройти полное медицинское обследование, вам достаточно всего лишь переступить порог клиники «Асмедика».
Здесь же вы узнаёте ваш точный диагноз (или о том, что вы здоровы – что еще приятнее) и проходите курс необходимого вам лечения. Наша обширная медицинская практика охватывает все основные области медицины. Это: стоматология, косметология, эстетические процедуры, гинекология, урология, кардиология, гастроэнтерология, эндокринология и даже гирудотерапия.
2) «В нужном месте в нужный момент».
Что это значит?
В «Асмедика» вас принимают без выходных. Вам нет необходимости брать отгулы на работе, теряя деньги и нервы.
Вам нет необходимости брать отгулы на работе, теряя деньги и нервы.
«Случай в Мадриде с госпожой К.» – Стиль – Коммерсантъ
Короткометражный фильм Ренаты Литвиновой в честь 130-летия ювелирного дома Carrera y Carrera
К юбилею испанского ювелирного дома Carrera y Carrera Рената Литвинова по собственному сценарию сняла короткометражный фильм «Случай в Мадриде с госпожой К.», исполнив в нем главную роль. Особая роль в фильме отведена драгоценностям Carrera y Carrera, созданным в разные периоды 130-летней истории ювелирного дома. В качестве костюмов были выбраны винтажные платья 1920–1970 годов, а сами съемки проходили в старинном мадридском отеле Ritz.
«Этот 15-минутный арт-фильм “Случай в Мадриде с госпожой К.” — история одной аферистки, даже не преступницы, а жертвы прекрасных украшений, в частности ожерелий и колец Carrera y Carrera,— рассказывает Рената Литвинова. — Дело в том, что я больше всего на свете люблю драгоценности, и, на мой взгляд, такие преступления вполне можно простить! Героиня нашего фильма — госпожа К.— крадет их не ради наживы, а для себя, не устояв перед соблазном обладания красотой! Сейчас я выступаю практически в роли адвоката моей героини, способной мечтать, воображать, желать и жить в своем воображаемом мире, где бриллианты тебе дарят незнакомцы, ничего не требуя взамен! Наша русская героиня уже даже не мечтает о конкретном принце, а мечтает о некоем джентльмене, который ей просто кладет под подушку “мечту”… и исчезает. Мы никогда его не увидим… Немного грустно, что его на самом деле никогда и не было! Но главное — способность мечтать. Как говорит наш персонаж в финале фильма: “Бойтесь своих желаний — они сбываются!”».
— Дело в том, что я больше всего на свете люблю драгоценности, и, на мой взгляд, такие преступления вполне можно простить! Героиня нашего фильма — госпожа К.— крадет их не ради наживы, а для себя, не устояв перед соблазном обладания красотой! Сейчас я выступаю практически в роли адвоката моей героини, способной мечтать, воображать, желать и жить в своем воображаемом мире, где бриллианты тебе дарят незнакомцы, ничего не требуя взамен! Наша русская героиня уже даже не мечтает о конкретном принце, а мечтает о некоем джентльмене, который ей просто кладет под подушку “мечту”… и исчезает. Мы никогда его не увидим… Немного грустно, что его на самом деле никогда и не было! Но главное — способность мечтать. Как говорит наш персонаж в финале фильма: “Бойтесь своих желаний — они сбываются!”».
«Такие преступления вполне можно простить!» — утверждает автор фильма Рената Литвинова в своем эссе, которое было опубликовано в «Ъ-Стиль. Украшения».
Режиссер, сценарист: Рената Литвинова
Операторы: Михаил Квирикадзе, Елена Сарапульцева и Сергей Гимро
В фильме снимались: Рената Литвинова, Ульяна Добровская, Александра Федорова, Любовь Инжиневская, Ремидиос Кабаллеро (Remedios Caballero), Хуан Мигель Тривиньо (Juan Miguel Triviño)
Бэкстейдж со съемок
Тег | htmlbook.
 ru
ru| Internet Explorer | Chrome | Opera | Safari | Firefox | Android | iOS |
| 1.0+ | 1.0+ | 1.0+ | 1.0+ | 1.0+ | 1.0+ | 1.0+ |
Спецификация
| HTML: | 3.2 | 4.01 | 5.0 | XHTML: | 1.0 | 1.1 |
Описание
Тег <img> предназначен для отображения на веб-странице изображений в графическом формате GIF, JPEG или PNG. Адрес файла с картинкой задаётся через атрибут src. Если необходимо, то рисунок можно сделать ссылкой на другой файл, поместив тег <img> в контейнер <a>. При этом вокруг изображения отображается рамка, которую можно убрать, добавив атрибут border=»0″ в тег <img>.
Рисунки также могут применяться в качестве карт-изображений, когда картинка
содержит активные области, выступающие в качестве ссылок. Такая карта по внешнему
виду ничем не отличается от обычного изображения, но при этом оно может быть
разбито на невидимые зоны разной формы, где каждая из областей служит ссылкой.
Такая карта по внешнему
виду ничем не отличается от обычного изображения, но при этом оно может быть
разбито на невидимые зоны разной формы, где каждая из областей служит ссылкой.
Синтаксис
| HTML | |
| XHTML | |
Атрибуты
- align
- Определяет как рисунок будет выравниваться по краю и способ обтекания текстом.
- alt
- Альтернативный текст для изображения.
- border
- Толщина рамки вокруг изображения.
- height
- Высота изображения.
- hspace
- Горизонтальный отступ от изображения до окружающего контента.
- ismap
- Говорит браузеру, что картинка является серверной картой-изображением.
- longdesc
- Указывает адрес документа, где содержится аннотация к картинке.

- lowsrc
- Адрес изображения низкого качества.
- src
- Путь к графическому файлу.
- vspace
- Вертикальный отступ от изображения до окружающего контента.
- width
- Ширина изображения.
- usemap
- Ссылка на тег <map>, содержащий координаты для клиентской карты-изображения.

Также для этого тега доступны универсальные атрибуты и события.
Закрывающий тег
Не требуется.
Пример
HTML5IECrOpSaFx
<!DOCTYPE HTML>
<html>
<head>
<meta charset="utf-8">
<title>Тег IMG</title>
</head>
<body>
<p><a href="lorem.html"><img src="images/girl.png"
alt="lorem"></a>
Lorem ipsum dolor sit amet...</p>
</body>
</html>Новости Тулы и области сегодня | Свежие тульские новости
Новости Тулы и области сегодня | Свежие тульские новости | ТСН24Новости ru-RU
- Все новости
- Армия и ОПК
- Культура
- Новости регионов
- Общество
- Политика
- Происшествия
- Спорт
- Экономика
- Погода
Фоторепортажи
Статьи
Афиша
- Все события
- Кино
- Концерты
- Театр
- Детям
- Фестивали
- Выставки
Видео
Обзоры
Авторские проекты
- Все проекты
- #Просто музыка
- Зверский футбол
- Карта Родины
- КОТельная
- ОПК
СМИ
15.
 8.4 Настройка параллелизма потоков для InnoDB
8.4 Настройка параллелизма потоков для InnoDB15.8.4 Настройка параллелизма потоков для InnoDB
InnoDB использует операционную систему
потоки для обработки запросов
от пользовательских транзакций. (Транзакции могут отправлять множество запросов к InnoDB перед фиксацией или откатом.)
современные операционные системы и серверы с многоядерными процессорами,
там, где переключение контекста эффективно, большинство рабочих нагрузок работают хорошо
без каких-либо ограничений на количество параллельных потоков.
В ситуациях, когда полезно свести к минимуму переключение контекста
между потоками InnoDB может использовать ряд
методы ограничения количества одновременно выполняемых операционных
системные потоки (и, следовательно, количество обрабатываемых запросов
в любое время). Когда InnoDB получает новый
запрос из пользовательской сессии, если количество потоков одновременно
выполняется с заранее определенным лимитом, новый запрос откладывается на
незадолго до новой попытки. Запрос, который не может быть
переносится после того, как сон помещается в очередь в порядке очереди
и в итоге перерабатывается. Потоки, ожидающие блокировок, не
подсчитывается в количестве одновременно выполняющихся потоков.
Запрос, который не может быть
переносится после того, как сон помещается в очередь в порядке очереди
и в итоге перерабатывается. Потоки, ожидающие блокировок, не
подсчитывается в количестве одновременно выполняющихся потоков.
Вы можете ограничить количество параллельных потоков, установив
параметр конфигурации innodb_thread_concurrency . Один раз
количество выполняемых потоков достигает этого предела, дополнительные
потоки спят на количество микросекунд, установленное
параметр конфигурации innodb_thread_sleep_delay , ранее
помещается в очередь.
Вы можете установить опцию конфигурации innodb_adaptive_max_sleep_delay на максимальное значение, которое вы позволили бы innodb_thread_sleep_delay и InnoDB автоматически настраивает innodb_thread_sleep_delay вверх или
вниз в зависимости от текущего планирования потоков. Этот
динамическая регулировка помогает механизму планирования потоков работать
плавно в периоды, когда система слабо загружена и когда
он работает почти на полную мощность.
Этот
динамическая регулировка помогает механизму планирования потоков работать
плавно в периоды, когда система слабо загружена и когда
он работает почти на полную мощность.
Значение по умолчанию для innodb_thread_concurrency и
подразумеваемое ограничение по умолчанию на количество одновременных потоков было
изменено в различных выпусках MySQL и ИнноДБ . Значение по умолчанию innodb_thread_concurrency — это 0 , так что по умолчанию нет ограничения на
количество одновременно выполняющихся потоков.
InnoDB заставляет потоки переходить в спящий режим только тогда, когда
количество одновременных потоков ограничено.Когда нет предела
количество потоков, все они утверждают, что должны быть запланированы одинаково. Который
есть, если innodb_thread_concurrency равно 0 , значение innodb_thread_sleep_delay — это
игнорируется.
Когда есть ограничение на количество потоков (когда innodb_thread_concurrency — это>
0), InnoDB снижает накладные расходы на переключение контекста
разрешая несколько запросов, сделанных во время выполнения одиночный оператор SQL для ввода InnoDB без соблюдения лимита, установленного innodb_thread_concurrency .С
оператор SQL (например, соединение) может состоять из нескольких строк
операции в пределах InnoDB , InnoDB назначает указанное количество
«Билеты», которые позволяют планировать поток
многократно с минимальными накладными расходами.
Когда запускается новый оператор SQL, у потока нет билетов, и он
должен соблюдать innodb_thread_concurrency . Один раз
поток имеет право ввести InnoDB , это
назначил количество билетов, которые он может использовать в дальнейшем
ввод InnoDB для выполнения строковых операций. Если
билеты заканчиваются, нить выселяется, и
Если
билеты заканчиваются, нить выселяется, и innodb_thread_concurrency — это
повторное наблюдение, что может привести к возвращению нити в
очередь ожидающих потоков first-in / first-out. Когда нить
снова имеет право ввести InnoDB , билеты
назначаются снова. Количество назначенных билетов определяется
глобальный вариант innodb_concurrency_tickets , который
по умолчанию 5000. Дан поток, ожидающий блокировки
один билет после того, как замок станет доступным.
Правильные значения этих переменных зависят от вашей среды.
и загруженность. Попробуйте использовать диапазон различных значений, чтобы определить, что
value работает для ваших приложений. Прежде чем ограничивать количество
одновременно выполняя потоки, просмотрите параметры конфигурации, которые
может улучшить производительность InnoDB на
многоядерные и многопроцессорные компьютеры, такие как innodb_adaptive_hash_index .
Для получения общей информации о производительности обработки потоков MySQL, см. раздел 5.1.12.1, «Интерфейсы подключения».
Что такое ads.txt? Простое руководство для издателей
Что такое ads.txt?
Ads.txt, также известный как «Авторизованные цифровые продавцы», представляет собой инициативу IAB Tech Lab по очистке и прозрачности цифровой рекламы за счет устранения возможности получения прибыли от поддельного инвентаря. Это достигается за счет предоставления издателям механизма, позволяющего объявить, кто имеет право продавать их ресурсы.
Хотя это почти сразу повлияло на издателей, в том числе на тех, кто просто использует AdSense, многие издатели до сих пор не знают об этом.Инициатива возникла после ряда скандалов, связанных с искажением информации об инвентаре рекламы, в результате чего большие деньги были потрачены на плохой инвентарь.
Решение, поддерживаемое IAB и большинством крупных игроков в рекламном пространстве, обманчиво простое (и на этот раз дешево и легко для издателей любого размера).
Вскоре после того, как в 2017 году был представлен файл ads.txt, Google объявил, что больше не будет покупать ресурсы на сайтах, на которых есть файл ads.txt, не соответствующий запросу объявления, поэтому издателям необходимо иметь свои объявления.txt правильно настроен сразу, если у них есть файл.
Выгодно ли было бы вам получить лучшую поддержку по таким вопросам?
OKO не только помогает веб-издателям зарабатывать больше, но и предоставляет экспертную поддержку с политикой и решениями для издателей, такими как Ads.txt. Узнайте больше здесь.
Как работает файл ads.txt?
Авторизованные цифровые продавцы — это просто текстовый файл, который находится на вашем сервере и перечисляет места, которые имеют право продавать рекламу от вашего имени. Идея проста: покупатели могут собирать эти данные и быть уверенными, что платят ли они за рекламу на Rollingstone.com, то здесь и будут появляться эти объявления (см. пример на сайте Rollingstone. com/ads.txt).
com/ads.txt).
Фактически, это файл, который издатели могут добавить на свой сайт, чтобы подтвердить свое право собственности на сайт и перечислить учетные записи, которым разрешено продавать свои ресурсы, делая это в формате, который можно легко сканировать и индексировать.
Что издатели выиграют от внедрения файла ads.txt?
Ads.txt полезен как издателям, так и рекламодателям. Если вы работаете в New York Times, преимущества очевидны: рекламодатели, желающие привлечь внимание к вашему сайту, не будут обмануты, купив неверно представленные ресурсы, и вы сохраните контроль над завышением цен.По мере того как стандарт получает все более широкое распространение, покупатели с большей вероятностью будут запрашивать файл ads.txt для всех покупок, что делает его более актуальным и для менее известных издателей.
Каковы недостатки реализации файла ads.txt?
Эта инициатива не обошлась без критики. Ads.txt разработан для обеспечения прозрачности, но некоторые утверждают, что он слишком прозрачен. Внедрение файла ads.txt показывает, где именно вы продаете свой инвентарь всем, кто хочет его найти.
Внедрение файла ads.txt показывает, где именно вы продаете свой инвентарь всем, кто хочет его найти.
Если вы по-разному оцениваете свой рекламный инвентарь по разным каналам, это позволяет покупателям делать покупки по самой низкой цене.Возьмем, к примеру, файл ads.txt для Business Insider:
.# Ads.txt uk.businessinsider.com
google.com, pub-1037373295371110, DIRECT #video, banner, native, app
rubiconproject.com, 10306, DIRECT #banner
indexexchange.com, 183963, DIRECT #banner
indexexchange.com, 184913, DIRECT #banner
openx .com, 537147789, DIRECT #banner
openx.com, 538986829, DIRECT #banner
appnexus.com, 7161, DIRECT #banner
appnexus.com, 3364, RESELLER #native
facebook.com, 1325898517502065, DIRECT #video, banner, app
liveintent.com, 87, DIRECT #banner
taboola.com, 688168, DIRECT #native
triplelift.com, 4139, DIRECT #native
teads.com, 11643, DIRECT # outstream
teads.com, 11445, DIRECT #outstream
google.
Если я покупаю рекламу на Business Insider через одного из этих партнеров, я могу легко увидеть, где еще доступен инвентарь. У меня даже есть соответствующие идентификаторы аккаунтов, если я захочу сравнить цены.
Business Insider пошли еще дальше и любезно пометили каждого партнера по спросу типами рекламы, которую они обслуживают, хотя это не является частью стандарта. Опять же, это «большие проблемы издателей», с которыми хотели бы столкнуться многие независимые компании, но о них также важно знать.
Следует ли издателям использовать файл ads.txt?
По сравнению с другими инициативами, которые поощряются издателями, стоимость внедрения файла ads.txt невероятно низка, и достаточно всего пяти минут работы, чтобы большинство сайтов соответствовали требованиям.По данным BuiltWith, 30% из 10 000 крупнейших веб-сайтов в настоящее время используют файл ads.txt, причем лидерами его внедрения являются США, Россия и Великобритания.
Низкая стоимость и простота внедрения означает, что это может подойти независимым издателям, которых не волнует проблема прозрачности и которые обладают гибкостью, чтобы легче исключить изменения.
Реализация файла ads.txt для Google AdSense и Google Ad Manager
Реализовать файл ads.txt невероятно просто. Создайте текстовый файл и добавьте по одной строке для каждого авторизованного партнера.В каждой строке добавьте следующие три части информации, разделенные запятой:
- Домен рекламной системы
- Ваш идентификатор аккаунта
- Тип отношений, которые у вас есть с этим партнером (ПРЯМЫЕ или ТОВАРЫ, если вы работаете через третью сторону)
Существует необязательное 4-е поле, которое представляет собой TAG ID источника, если они сертифицированы Trustworthy Accountability Group. После создания просто загрузите этот файл на свой веб-сервер, чтобы он был виден на примере.com / ads.txt, и все готово.
Google упорно толкая на ads. txt. Хотя они не заявили, что прекратят делать ставки на инвентарь, для которого нет соответствующего файла ads.txt, они прекратят покупать и продавать неавторизованный инвентарь в четвертом квартале 2017 года.
txt. Хотя они не заявили, что прекратят делать ставки на инвентарь, для которого нет соответствующего файла ads.txt, они прекратят покупать и продавать неавторизованный инвентарь в четвертом квартале 2017 года.
На практике это означает, что для издателей AdSense и Ad Exchange существует более непосредственный риск из-за неправильной реализации файла ads.txt, чем из-за его неиспользования. Это делает вдвойне важным убедиться, что:
- Если вы используете рекламу.txt, вы должны включить декларации для обслуживаемых аккаунтов AdSense и Ad Exchange
- Эти декларации должны быть правильными
Авторизованные продавцы цифрового контента для AdSense
Если вы публикуете рекламу через Google AdSense и хотите реализовать файл ads.txt, вам необходимо сначала определить свой идентификатор издателя. Его можно найти, войдя в AdSense и выбрав «Настройки»> «Учетная запись»> «Информация об учетной записи».
Ваш идентификатор издателя имеет формат pub-0000000000000000, где нули заменены вашим собственным 16-значным числом.
Запись в файле ads.txt для собственной учетной записи Google AdSense издателя будет выглядеть так:
google.com, pub-0000000000000000, ПРЯМОЙ, f08c47fec0942fa0
Обратите внимание, что TAGID для Google всегда f08c47fec0942fa0. Кроме того, не забудьте указать издательскую часть своего идентификатора издателя, поскольку это, по-видимому, одна из самых распространенных ошибок при реализации файла ads.txt для издателей AdSense.
Многие издатели AdSense видят в своих аккаунтах предупреждения относительно рекламы.текст . В предупреждении указано:
Заработок под угрозой. Один или несколько файлов ads.txt не содержат вашего идентификатора издателя AdSense. Исправьте эту проблему сейчас, чтобы не сильно повлиять на ваш доход.
Это предупреждение для учетной записи дополняет уведомления, отправляемые по электронной почте в следующем формате:
Уважаемый издатель!
Мы заметили, что в файле ads.
С середины октября Google перестанет покупать рекламу на сайтах с файлами ads.txt без правильных идентификаторов издателей. Мы рекомендуем вам немедленно обновить файлы ads.txt, чтобы не повлиять на ваши доходы. Убедитесь, что файл ads.txt для каждого сайта, который вы хотите монетизировать с помощью этой учетной записи, содержит следующий фрагмент:
google.com, pub-xxxxxxxxxxxxxxxx, DIRECT, f08c47fec0942fa0
Обработка обновленных объявлений AdSense может занять до 24 часов. .txt файлы.
Вы можете узнать больше об объявлениях.txt, о том, как покупатели будут использовать его и как внедрить на своих сайтах, — в нашем Справочном центре.
 txt на одном или нескольких ваших сайтах, которые вы монетизируете через этот аккаунт AdSense (pub-xxxxxxxxxxxxxxxx), отсутствует правильный код издателя.
txt на одном или нескольких ваших сайтах, которые вы монетизируете через этот аккаунт AdSense (pub-xxxxxxxxxxxxxxxx), отсутствует правильный код издателя.Авторизованные цифровые продавцы для Google Ad Manager
Настройка для издателей с их собственной прямой учетной записью Google Ad Manager такая же, с идентификатором, который можно найти через GAM, перейдя в Админ> Глобальные настройки> Все настройки сети. И снова идентификатор издателя имеет формат pub-0000000000000000.
И снова идентификатор издателя имеет формат pub-0000000000000000.
Для издателей, получающих доступ к Ad Exchange через GCPP (например, OKO) или через стороннюю организацию, процесс такой же, но им нужно будет получить идентификатор издателя от своего управляющего партнера и указать его в качестве торгового посредника.
Если взять пример с издателем, использующим свою учетную запись AdSense и получающим доступ к Ad Exchange через партнера, его файл ads.txt будет выглядеть, как показано ниже (для ясности мы помечены # комментарием):
google.com, pub-0000000000000001, DIRECT, f08c47fec0942fa0 # own adsense
google.com, pub-0000000000000002, RESELLER, f08c47fec0942fa0 # AdX
Издатели OKO могут просматривать необходимые записи ads.txt в пользовательском интерфейсе Lens. Узнайте больше здесь.
Примечание. Эта статья была первоначально опубликована 7 сентября 2017 г. и обновлена в декабре 2019 г., чтобы гарантировать, что мы предоставили наиболее точную информацию.

Mat поддерживает создателей контента в Интернете с 1996 года. Как соучредитель OKO Digital, Мэт стал первым человеком в Великобритании, получившим статус партнера AdSense, и повторил это первым с программой сертифицированных партнеров Google по публикации.
Обнаружение поддельной личности с помощью неожиданных вопросов и динамики мыши
Abstract
Обнаружение поддельных идентификационных данных — серьезная проблема безопасности.Современные методы обнаружения памяти использовать нельзя, поскольку они требуют предварительного знания истинной личности респондента. Здесь мы сообщаем о новом методе обнаружения поддельных идентификационных данных, основанном на использовании неожиданных вопросов, которые могут быть использованы для проверки личности респондента без какой-либо предварительной автобиографической информации. В то время как рассказчики правды автоматически отвечают на неожиданные вопросы, лжецы должны «строить» и проверять свои ответы. Этот недостаток автоматизма отражается в движениях мыши, используемых для записи ответов, а также в количестве ошибок.Ответы на неожиданные вопросы сравниваются с ответами на ожидаемые и контрольные вопросы (т. Е. Вопросы, на которые лжец также должен отвечать правдиво). Параметры, которые кодируют движение мыши, были проанализированы с использованием классификаторов машинного обучения, и результаты показывают, что траектории мыши и ошибки в неожиданных вопросах эффективно отличают лжецов от правдивых. Кроме того, мы показали, что лжецы могут быть идентифицированы также, когда они отвечают правдиво. Неожиданные вопросы в сочетании с анализом движения мыши могут эффективно выявить участников с поддельными именами без необходимости получения какой-либо предварительной информации об испытуемом.
Этот недостаток автоматизма отражается в движениях мыши, используемых для записи ответов, а также в количестве ошибок.Ответы на неожиданные вопросы сравниваются с ответами на ожидаемые и контрольные вопросы (т. Е. Вопросы, на которые лжец также должен отвечать правдиво). Параметры, которые кодируют движение мыши, были проанализированы с использованием классификаторов машинного обучения, и результаты показывают, что траектории мыши и ошибки в неожиданных вопросах эффективно отличают лжецов от правдивых. Кроме того, мы показали, что лжецы могут быть идентифицированы также, когда они отвечают правдиво. Неожиданные вопросы в сочетании с анализом движения мыши могут эффективно выявить участников с поддельными именами без необходимости получения какой-либо предварительной информации об испытуемом.
Образец цитирования: Monaro M, Gamberini L, Sartori G (2017) Выявление поддельной личности с помощью неожиданных вопросов и динамики мыши. PLoS ONE 12 (5):
e0177851. https://doi.org/10.1371/journal.pone.0177851
https://doi.org/10.1371/journal.pone.0177851
Редактор: Чжун-Кэ Гао, Тяньцзиньский университет, КИТАЙ
Поступила: 10 января 2017 г .; Принято к печати: 4 мая 2017 г .; Опубликовано: 18 мая 2017 г.
Авторские права: © 2017 Monaro et al.Это статья в открытом доступе, распространяемая в соответствии с условиями лицензии Creative Commons Attribution License, которая разрешает неограниченное использование, распространение и воспроизведение на любом носителе при условии указания автора и источника.
Доступность данных: Все соответствующие данные находятся в документе и его файлах с вспомогательной информацией.
Финансирование: Автор (ы) не получил специального финансирования для этой работы.
Конкурирующие интересы: Авторы заявили, что конкурирующих интересов не существует.
Введение
Использование поддельных идентификационных данных — очень распространенная проблема. Люди могут подделывать свою личную информацию по ряду причин. Фальшивая автобиографическая информация, например, наблюдается в спорте, когда игроки утверждают, что они моложе, чем они есть на самом деле [1]. Социальные сети изобилуют фальшивыми профилями [2]. Поддельная личность также является серьезной проблемой в сфере безопасности [3]. Фактически считается, что большое количество террористов скрывается среди мигрантов с Ближнего Востока, въезжающих в Европу.Обычно у мигрантов нет документов, и их идентификационные данные часто основываются на самодекларировании. Считается, что среди мигрантов большое количество террористов выдают ложные имена при въезде на границу. Например, один из террористов, участвовавших в подрыве террориста-смертника в аэропорту Брюсселя 22 марта 2016 г., использовал личность бывшего футболиста миланского «Интера» [4]. В этих случаях инструменты биометрической идентификации (например, отпечатки пальцев) не могли быть применены, поскольку большинство подозреваемых ранее были неизвестны.
Люди могут подделывать свою личную информацию по ряду причин. Фальшивая автобиографическая информация, например, наблюдается в спорте, когда игроки утверждают, что они моложе, чем они есть на самом деле [1]. Социальные сети изобилуют фальшивыми профилями [2]. Поддельная личность также является серьезной проблемой в сфере безопасности [3]. Фактически считается, что большое количество террористов скрывается среди мигрантов с Ближнего Востока, въезжающих в Европу.Обычно у мигрантов нет документов, и их идентификационные данные часто основываются на самодекларировании. Считается, что среди мигрантов большое количество террористов выдают ложные имена при въезде на границу. Например, один из террористов, участвовавших в подрыве террориста-смертника в аэропорту Брюсселя 22 марта 2016 г., использовал личность бывшего футболиста миланского «Интера» [4]. В этих случаях инструменты биометрической идентификации (например, отпечатки пальцев) не могли быть применены, поскольку большинство подозреваемых ранее были неизвестны. Интересно, что методы обнаружения в принципе могут быть применены.
Интересно, что методы обнаружения в принципе могут быть применены.
С самого начала, начиная с пионерской работы Бенусси [5], идентификация обманчивых реакций в основном основывалась на использовании физиологических показателей [6]. Совсем недавно были внедрены методы, основанные на времени реакции (RT). Они основаны на задержках реакции на представленный интересующий стимул. Существует широкий консенсус относительно того факта, что обман когнитивно сложнее, чем установление истины, и что эта более высокая когнитивная сложность отражается в ряде показателей когнитивных усилий, включая, например, время реакции [7].Есть свидетельства того, что процесс подавления правдивого ответа, который активируется автоматически, и замена его обманчивым ответом может быть сложной когнитивной задачей. Однако в некоторых случаях ответить ложью быстрее, чем правдиво [8]. Фактически, различные типы лжи могут различаться по своей когнитивной сложности и могут требовать разного уровня когнитивных усилий. Например, когнитивные усилия могут быть минимальными, когда субъект просто отрицает факт, который действительно произошел.
Например, когнитивные усилия могут быть минимальными, когда субъект просто отрицает факт, который действительно произошел.
Напротив, он может быть очень высоким при фабрикации сложной лжи, например, когда Улисс, герой Одиссеи , сказал Полифему, что его настоящее имя — Ничей. Эта ложь была направлена на то, чтобы обмануть Полифема, но также должна была быть легко распознана одноглазыми товарищами Полифема как ложь.
Обнаружение памяти на основе RT имеет ряд преимуществ по сравнению с альтернативными психофизиологическими методами, особенно когда большое количество субъектов находится под пристальным вниманием. Во-первых, RT менее чувствительны к сильным индивидуальным изменениям или изменениям окружающей среды, например, в случае физиологических параметров.Во-вторых, этот метод имеет беспрецедентную особенность, заключающуюся в том, что его можно применять, используя просто компьютер, и применять к большому количеству испытуемых через Интернет. В настоящее время два метода обнаружения памяти, основанные на RT, которые используются для представления слов или предложений, могут быть адаптированы в качестве инструментов для проверки личности. Тест на скрытую информацию (CIT-RT) [9] и автобиографический тест на неявную ассоциацию (aIAT) [10] — это методы, основанные на RT, которые прошли тщательную проверку с удовлетворительными результатами [11].
Тест на скрытую информацию (CIT-RT) [9] и автобиографический тест на неявную ассоциацию (aIAT) [10] — это методы, основанные на RT, которые прошли тщательную проверку с удовлетворительными результатами [11].
CIT-RT — это метод, который состоит из представления важной информации в ряду очень похожих некритических источников отвлекающей информации. Например, если скрытая информация об орудии убийства находится под пристальным вниманием, нож (известное орудие убийства) будет представлен вместе с отвлекающими элементами, которые также являются потенциальным орудием убийства (например, пистолет и т. Д.). Ожидается, что невинные испытуемые будут реагировать на все стимулы. Напротив, для виновного субъекта (со знанием дела о вине) ожидаются более длительные ответы по критическому пункту (например,г., нож). При применении для проверки того, соответствует ли автобиографическая информация, которую утверждает испытуемый, истинной личности, CIT эффективно распознает личности лжецов и правдивых [11].
AIAT — это методика обнаружения памяти, которая использует согласованность / несогласованность между предложениями. Он включает стимулы, принадлежащие к четырем категориям: две из них являются логическими категориями, представленными предложениями, которые безусловно истинны (например, « Я перед компьютером ») или, безусловно, ложны (например, « Я перед компьютером, »).g., « Я поднимаюсь на гору ») для респондента и относящиеся к моменту тестирования. Две другие категории представлены альтернативными версиями исследуемой автобиографической памяти (например, « Я поехал в Париж на Рождество » против « Я поехал в Лондон на Рождество »), причем только одна из двух верна. . Во время теста испытуемый выполняет задачу категоризации. Истинное автобиографическое событие идентифицируется, потому что оно определяет более быстрые RT при совместном использовании одной и той же моторной реакции с определенно верными предложениями [12].
Что касается средней точности классификации основанных на RT методов обнаружения лжи, CIT [9] и aIAT [10] имеют такую же точность, что и описанные здесь эксперименты (около 90%). Таким образом, описываемая здесь методика имеет такую же точность, что и современные методы обнаружения лжи на основе RT. Тем не менее, у aIAT и CIT есть важное ограничение: оба требуют, чтобы в тест была включена информация об истинной идентичности. CIT-RT противопоставляет информацию об истинной личности информации о фальшивой личности [11].AIAT также построен таким образом, что из двух контрастирующих воспоминаний одно должно быть истинным, а другое — ложным [10]. Если мы построим aIAT только с заявленной (поддельной) идентичностью, у нас будут две ложные памяти, и тест не будет удовлетворять одному из основных ограничений в применении процедуры. Таким образом, это ограничение доступных методов является серьезной проблемой для приложений в реальных условиях, даже если Мейксер и Розенфельд [13] сделали шаг в этом направлении.Фактически, в большинстве случаев расследования истинная личность субъекта полностью неизвестна экзаменатору, который заинтересован в оценке того, является ли заявленная личность истинной или нет.
Таким образом, описываемая здесь методика имеет такую же точность, что и современные методы обнаружения лжи на основе RT. Тем не менее, у aIAT и CIT есть важное ограничение: оба требуют, чтобы в тест была включена информация об истинной идентичности. CIT-RT противопоставляет информацию об истинной личности информации о фальшивой личности [11].AIAT также построен таким образом, что из двух контрастирующих воспоминаний одно должно быть истинным, а другое — ложным [10]. Если мы построим aIAT только с заявленной (поддельной) идентичностью, у нас будут две ложные памяти, и тест не будет удовлетворять одному из основных ограничений в применении процедуры. Таким образом, это ограничение доступных методов является серьезной проблемой для приложений в реальных условиях, даже если Мейксер и Розенфельд [13] сделали шаг в этом направлении.Фактически, в большинстве случаев расследования истинная личность субъекта полностью неизвестна экзаменатору, который заинтересован в оценке того, является ли заявленная личность истинной или нет.
Этот документ можно рассматривать как доказательство концепции, репрезентативный пример типов проблем, которые не могут быть решены с помощью современных научно обоснованных методов обнаружения лжи (CIT и aIAT). Доступные методы не могут быть использованы, когда критическая информация, которая оценивается на достоверность (в данном случае, настоящая личность респондента, который пытается скрыть свою личность), недоступна.
Здесь мы представим новую парадигму, которая преодолевает недостатки доступных методов и может использоваться для определения правдивости личной информации. Что наиболее важно, мы покажем, что поддельные личности могут быть обнаружены при отсутствии какой-либо информации об истинной личности подозреваемого. Поддельные личности будут обнаружены с помощью неожиданных вопросов в сочетании с анализом движений мыши во время ответа в задаче двоичной классификации. Мы покажем, что анализ динамики мыши эффективно определяет, верна ли личная информация, которую утверждает испытуемый. В представленных здесь экспериментах участники не реагируют, нажимая кнопки ДА / НЕТ с помощью клавиатуры, как в RT-CIT или aIAT, но вместо этого от них требуется реагировать, щелкая виртуальные кнопки мыши, появляющиеся на экране компьютера вдоль с вопросами относительно их личности. Использование мыши для записи ответов имеет ряд преимуществ по сравнению с использованием клавиатуры. В то время как нажатие кнопки может разрешить запись только RT, запись с помощью мыши позволяет собирать несколько индикаторов, включая, но не ограничиваясь, RT (например.g., скорость, ускорение и траектория). Этот метод также является многообещающим с точки зрения устойчивости к контрмерам, поскольку большое количество параметров движения кажется, в принципе, более сложным для полного контроля с помощью эффективных, запланированных контрмер для обнаружения лжи.
В представленных здесь экспериментах участники не реагируют, нажимая кнопки ДА / НЕТ с помощью клавиатуры, как в RT-CIT или aIAT, но вместо этого от них требуется реагировать, щелкая виртуальные кнопки мыши, появляющиеся на экране компьютера вдоль с вопросами относительно их личности. Использование мыши для записи ответов имеет ряд преимуществ по сравнению с использованием клавиатуры. В то время как нажатие кнопки может разрешить запись только RT, запись с помощью мыши позволяет собирать несколько индикаторов, включая, но не ограничиваясь, RT (например.g., скорость, ускорение и траектория). Этот метод также является многообещающим с точки зрения устойчивости к контрмерам, поскольку большое количество параметров движения кажется, в принципе, более сложным для полного контроля с помощью эффективных, запланированных контрмер для обнаружения лжи.
Было показано, что анализ траекторий мыши может улавливать когнитивную сложность обработки стимулов, когда участники должны давать ответы с множественным выбором. Эта процедура применялась к большому количеству областей и оказалась полезной для выявления когнитивной сложности, связанной с проверкой отрицательных предложений [14], расовыми установками [15], восприятием [16], предполагаемой памятью [17] и лексическими решениями [18]. ].Duran et al. представили новаторское расследование по детекции лжи [19]. Авторы записывали двигательные траектории (авторы не использовали мышь для записи ответов, а скорее контроллер Nintendo Wii), в то время как испытуемые выполняли задание лежа. Во время задания участники должны были отвечать правдиво или лгать на представленные предложения, как это было проиндексировано визуальной подсказкой. Анализ двигательных траекторий привел к интересным результатам. Инструктированная ложь можно отличить от правдивых ответов по нескольким параметрам, включая время запуска двигателя, общее время, необходимое для ответа, траекторию движения и кинематические параметры, такие как скорость и ускорение.Их эксперимент выявил тот факт, что когнитивный конфликт, вызванный ложью, влияет на траекторию реакции, но не продемонстрировал напрямую его эффективность в отнесении лиц, вводящих в заблуждение, от лиц, говорящих правду.
Эта процедура применялась к большому количеству областей и оказалась полезной для выявления когнитивной сложности, связанной с проверкой отрицательных предложений [14], расовыми установками [15], восприятием [16], предполагаемой памятью [17] и лексическими решениями [18]. ].Duran et al. представили новаторское расследование по детекции лжи [19]. Авторы записывали двигательные траектории (авторы не использовали мышь для записи ответов, а скорее контроллер Nintendo Wii), в то время как испытуемые выполняли задание лежа. Во время задания участники должны были отвечать правдиво или лгать на представленные предложения, как это было проиндексировано визуальной подсказкой. Анализ двигательных траекторий привел к интересным результатам. Инструктированная ложь можно отличить от правдивых ответов по нескольким параметрам, включая время запуска двигателя, общее время, необходимое для ответа, траекторию движения и кинематические параметры, такие как скорость и ускорение.Их эксперимент выявил тот факт, что когнитивный конфликт, вызванный ложью, влияет на траекторию реакции, но не продемонстрировал напрямую его эффективность в отнесении лиц, вводящих в заблуждение, от лиц, говорящих правду. Короче говоря, метод, который исследовали авторы, может быть использован для определения того, когда правдивый лжет, но не когда лжец лжет, поскольку их процедура сравнивает в пределах одного и того же говорящего правду субъекта правдивые ответы с лживыми ответами.
Короче говоря, метод, который исследовали авторы, может быть использован для определения того, когда правдивый лжет, но не когда лжец лжет, поскольку их процедура сравнивает в пределах одного и того же говорящего правду субъекта правдивые ответы с лживыми ответами.
Здесь мы представим результаты эксперимента, в котором траектории двигательных реакций с использованием мыши были исследованы, в то время как участники были проверены на вопросы, касающиеся их личности.Было задано два типа вопросов: ожидаемые вопросы и неожиданные вопросы [20]. Vrij и соавторы [21] первыми начали использовать неожиданные вопросы, и растет экспериментальная поддержка идеи о том, что во время следственного интервью обманчивые предметы будут легче обнаруживать с помощью неожиданных вопросов, а не ожидаемых вопросов [22]. Было показано, что лжецы планируют возможные интервью, репетируя вопросы, которые, как они ожидают, также будут заданы [23]. Лжецы дают свои запланированные ответы на ожидаемые вопросы легко и быстро, но им необходимо придумать правдоподобные ответы в случае неожиданных вопросов, а это приводит к увеличению когнитивной нагрузки. Напротив, правдивые ответы не страдают из-за побочных эффектов когнитивной нагрузки, поскольку они довольно автоматические и не требуют усилий как для ожидаемых, так и для неожиданных вопросов. Используя методологию неожиданных вопросов в следственном интервью, Lancaster et al. [24] сообщили о хороших показателях классификации как для говорящих правду (78%), так и для лжецов (83%). Lancaster et al. Результаты [24] наблюдались путем сравнения разницы в количестве деталей, сообщаемых при ответах на ожидаемые и неожиданные вопросы.Короче говоря, лжецы, говоря правду, сообщают гораздо больше деталей на ожидаемые вопросы, а не на неожиданные, и обнаружение лжи может извлечь выгоду из этой разницы.
Напротив, правдивые ответы не страдают из-за побочных эффектов когнитивной нагрузки, поскольку они довольно автоматические и не требуют усилий как для ожидаемых, так и для неожиданных вопросов. Используя методологию неожиданных вопросов в следственном интервью, Lancaster et al. [24] сообщили о хороших показателях классификации как для говорящих правду (78%), так и для лжецов (83%). Lancaster et al. Результаты [24] наблюдались путем сравнения разницы в количестве деталей, сообщаемых при ответах на ожидаемые и неожиданные вопросы.Короче говоря, лжецы, говоря правду, сообщают гораздо больше деталей на ожидаемые вопросы, а не на неожиданные, и обнаружение лжи может извлечь выгоду из этой разницы.
Описанный здесь эксперимент состоит из задачи бинарной классификации, включающей ожидаемые и неожиданные вопросы об идентичности. Ожидаемые вопросы касались типичной информации, представленной в документах, в то время как неожиданные вопросы касались информации, которая была хорошо известна и автоматически извлекалась правдой, но лжецы должны были «вычислить на месте».![]() Примером ожидаемого вопроса может быть дата рождения, а соответствующим неожиданным вопросом может быть зодиак, соответствующий дате рождения. В то время как правдивые люди легко проверяют вопросы, связанные с зодиаком, лжецы не знают зодиака немедленно, и им приходится вычислять его для правильной проверки. Неопределенность при ответе на неожиданные вопросы может привести к ошибкам. Кроме того, мы обнаружили, что траектория реакции мыши, проанализированная с использованием кинематических параметров и других пространственных и временных параметров, предназначенных для определения неопределенности двигательной реакции, может быть полезна при обнаружении обмана.Следовательно, ожидается, что обман будет отражаться в форме траекторий.
Примером ожидаемого вопроса может быть дата рождения, а соответствующим неожиданным вопросом может быть зодиак, соответствующий дате рождения. В то время как правдивые люди легко проверяют вопросы, связанные с зодиаком, лжецы не знают зодиака немедленно, и им приходится вычислять его для правильной проверки. Неопределенность при ответе на неожиданные вопросы может привести к ошибкам. Кроме того, мы обнаружили, что траектория реакции мыши, проанализированная с использованием кинематических параметров и других пространственных и временных параметров, предназначенных для определения неопределенности двигательной реакции, может быть полезна при обнаружении обмана.Следовательно, ожидается, что обман будет отражаться в форме траекторий.
Методы
В задаче проверки личности лжецы обычно должны узнать автобиографическую информацию о новой личности и пройти тест, отвечая так, как если бы эта информация была для них реальной. Например, Verschuere et al. [11] попросили испытуемых принять фальшивую личность, репетировать и вспоминать ее до тех пор, пока их выступление не станет безошибочным. Затем от лжецов требовалось отреагировать так, как если бы их новая личность была истинной.Точно так же здесь мы требовали, чтобы обманывающие участники познали новую личность. Во время сеанса тестирования участникам задавали как ожидаемые, так и неожиданные вопросы об их личной информации. Ожидаемые вопросы включали информацию о ложной личности, которая была назначена лжецам и репетировалась перед тестом до тех пор, пока испытуемые не совершили никаких ошибок. Говорящие правду репетировали свои истинные личности. Ожидаемые вопросы касались типичной информации, содержащейся в идентификационной карте (например,г., имя, фамилия, дата рождения, место рождения). Напротив, неожиданными вопросами были вопросы, связанные с личностью, на которые испытуемые не были готовы отвечать. Эти неожиданные вопросы были непосредственно получены из ожидаемых вопросов (например, возраст личности и знак зодиака определяются по дате рождения; в то время как вопросы о дате рождения ожидаются, вопросы о возрасте и знаке зодиака являются неожиданными).
Затем от лжецов требовалось отреагировать так, как если бы их новая личность была истинной.Точно так же здесь мы требовали, чтобы обманывающие участники познали новую личность. Во время сеанса тестирования участникам задавали как ожидаемые, так и неожиданные вопросы об их личной информации. Ожидаемые вопросы включали информацию о ложной личности, которая была назначена лжецам и репетировалась перед тестом до тех пор, пока испытуемые не совершили никаких ошибок. Говорящие правду репетировали свои истинные личности. Ожидаемые вопросы касались типичной информации, содержащейся в идентификационной карте (например,г., имя, фамилия, дата рождения, место рождения). Напротив, неожиданными вопросами были вопросы, связанные с личностью, на которые испытуемые не были готовы отвечать. Эти неожиданные вопросы были непосредственно получены из ожидаемых вопросов (например, возраст личности и знак зодиака определяются по дате рождения; в то время как вопросы о дате рождения ожидаются, вопросы о возрасте и знаке зодиака являются неожиданными). Например, если субъект репетировал год рождения, указанный на поддельном удостоверении личности (например,g., 1988), неожиданный вопрос, связанный с рождением, был о возрасте (например, 38).
Например, если субъект репетировал год рождения, указанный на поддельном удостоверении личности (например,g., 1988), неожиданный вопрос, связанный с рождением, был о возрасте (например, 38).
Для правдивого респондента предполагается, что неожиданные вопросы автоматически вызывают правильный ответ. Напротив, лжец должен воссоздать непредсказуемую неожиданную информацию и проверить ее. Следовательно, этот процесс требует времени до отправки ответа, что отражается в более длительных RT. Короче говоря, «Неожиданные вопросы увеличат когнитивную нагрузку лжеца» [20], и ожидается, что это отразится не только на RT и количестве ошибок, но и на траекториях движения мыши.
Далее мы подробно опишем структуру эксперимента и собранные меры. Комитет по этике психологических исследований Университета Падуи одобрил экспериментальную процедуру.
Участники
Сорок италоязычных участников были набраны на факультете психологии Университета Падуи. Выборка состояла из 17 мужчин и 23 женщин. Их средний возраст составлял 25 лет (SD = 4,6), а средний уровень образования — 17 лет (SD = 1.8). Все участники были правши. Эти первые 40 участников были использованы для разработки модели, которая позже была протестирована для обобщения в новой группе из 20 итальянскоязычных участников (10 лжецов и 10 рассказчиков правды). Вторая выборка состояла из 9 мужчин и 11 женщин. Их средний возраст составлял 23 года (SD = 1,5), а средний уровень образования — 17 лет (SD = 0,83). Обе группы испытуемых предоставили информированное согласие перед экспериментом.
Их средний возраст составлял 25 лет (SD = 4,6), а средний уровень образования — 17 лет (SD = 1.8). Все участники были правши. Эти первые 40 участников были использованы для разработки модели, которая позже была протестирована для обобщения в новой группе из 20 итальянскоязычных участников (10 лжецов и 10 рассказчиков правды). Вторая выборка состояла из 9 мужчин и 11 женщин. Их средний возраст составлял 23 года (SD = 1,5), а средний уровень образования — 17 лет (SD = 0,83). Обе группы испытуемых предоставили информированное согласие перед экспериментом.
Стимулы
Тридцать два предложения, отображаемые в верхней части экрана компьютера, были представлены всем участникам.Квадраты, представляющие ответы ДА и НЕТ, были расположены в верхнем левом и верхнем правом углу экрана компьютера. Шестнадцать предложений требовали ответа ДА, а 16 предложений требовали ответа НЕТ, как для лжецов, так и для рассказчиков правды. 32 экспериментальным вопросам предшествовали 6 обучающих вопросов (3 требовали ответа ДА и 3 требовали ответа НЕТ) по вопросам, связанным с личностью, не включенным в сам эксперимент (например, «Ваш вес 51 кг?»). Предложения, требующие ответа ДА, относятся к следующим категориям:
Предложения, требующие ответа ДА, относятся к следующим категориям:
- Ожидаемые вопросы: они включали информацию, которая была отрепетирована перед экспериментом, как для правдивых, так и для лжецов.Лжецы ответили личной информацией о фальшивых профилях личности, которые им назначил экспериментатор. Правды ответили на вопросы относительно их истинной личности.
- Неожиданные вопросы: Неожиданные вопросы включали информацию, тесно связанную с ложными именами, но не репетированную явно перед экспериментом ни правдивыми, ни лжецами. В этом случае лжецы ответили на информацию, относящуюся к присвоенным им фальшивым именам, в то время как рассказчики правды ответили на вопросы об их истинных именах.
- Контрольные вопросы: Контрольные вопросы смешивались с ожидаемыми и неожиданными вопросами. Контрольные вопросы ( n = 8; 4 требовали ответа ДА и 4 ответа НЕТ) включали личную информацию, на которую испытуемые должны были ответить правдиво, потому что они не могли быть скрыты от экзаменатора, наблюдающего за тестом. Например, « Вы мужчина ?» (для мужчины) требовал ответа ДА, тогда как « Вы женщина ?» (для мужчины) не требовал ответа.Следовательно, контрольные вопросы требовали правдивых ответов как лжецов, так и рассказчиков правды, даже если они были связаны с личностью.
 Например, « Вы мужчина ?» (для мужчины) требовал ответа ДА, тогда как « Вы женщина ?» (для мужчины) не требовал ответа.Следовательно, контрольные вопросы требовали правдивых ответов как лжецов, так и рассказчиков правды, даже если они были связаны с личностью.
Например, « Вы мужчина ?» (для мужчины) требовал ответа ДА, тогда как « Вы женщина ?» (для мужчины) не требовал ответа.Следовательно, контрольные вопросы требовали правдивых ответов как лжецов, так и рассказчиков правды, даже если они были связаны с личностью.И для лжецов, и для рассказчиков правды половина ожидаемых, неожиданных и контрольных вопросов ( n = 16) требовала ответов ДА. Напротив, 16 вопросов, полученных из ожидаемых, неожиданных и контрольных вопросов, не требовали ответов, как показано в таблице 1.
Как видно из Таблицы 2, ответы лжецов и рассказчиков правды различались только ожидаемыми и неожиданными ответами ДА.Фактически, для лжецов ожидаемые и неожиданные вопросы относительно их поддельной личности на самом деле не были ответами, которые, поскольку они лгали, требовали ответов ДА. Другими словами, только вопросы с ожидаемыми и неожиданными ответами ДА различали две группы, потому что правдивые люди отвечали искренне, а лжецы обманывали. На все остальные вопросы (контроль ДА, контроль НЕТ, ожидаемое НЕТ, неожиданное НЕТ) и лжецы, и рассказчики правды ответили правдиво.
На все остальные вопросы (контроль ДА, контроль НЕТ, ожидаемое НЕТ, неожиданное НЕТ) и лжецы, и рассказчики правды ответили правдиво.
Методика эксперимента
Эксперимент проводился с использованием программы MouseTracker [25].Двадцать участников ответили правдиво, в то время как остальным было дано указание солгать о своей личности в соответствии с ложным профилем, который был чрезмерно изучен перед началом эксперимента, согласно Verschuere et al. [11]. 20 лжецов были проинструктированы узнать ложную личность по поддельному итальянскому удостоверению личности, к которому была прикреплена фотография субъекта и который также сообщил ложные личные данные. После этапа обучения участники дважды вспомнили информацию, которую они прочитали на удостоверении личности.Между двумя отзывами от них требовалось выполнить некоторую ментальную арифметику в качестве отвлекающего задания. С другой стороны, рассказчики правды также выполняли мысленную арифметику и проверяли свои настоящие автобиографические данные только один раз перед началом эксперимента. Во время экспериментального задания 6 ожидаемых вопросов, 6 неожиданных вопросов и 4 контрольных вопроса, описанных выше, были представлены в случайном порядке. Для каждого из 16 вопросов, на которые требовался ответ «ДА», был представлен аналогичный вопрос, требующий отрицательного ответа.Каждый участник ответил на 32 вопроса плюс 6 учебных вопросов, которые не были включены в анализ. В половине случаев вопрос ДА появлялся первым, а в другой половине — вторым. Участники инициировали представление каждого вопроса, нажимая кнопку СТАРТ, которая появлялась в центре нижней части экрана компьютера. Ответ давался нажатием одной из двух кнопок ответа, появляющихся в верхней части экрана компьютера, одной в верхнем левом углу и одной в правом верхнем углу.
Во время экспериментального задания 6 ожидаемых вопросов, 6 неожиданных вопросов и 4 контрольных вопроса, описанных выше, были представлены в случайном порядке. Для каждого из 16 вопросов, на которые требовался ответ «ДА», был представлен аналогичный вопрос, требующий отрицательного ответа.Каждый участник ответил на 32 вопроса плюс 6 учебных вопросов, которые не были включены в анализ. В половине случаев вопрос ДА появлялся первым, а в другой половине — вторым. Участники инициировали представление каждого вопроса, нажимая кнопку СТАРТ, которая появлялась в центре нижней части экрана компьютера. Ответ давался нажатием одной из двух кнопок ответа, появляющихся в верхней части экрана компьютера, одной в верхнем левом углу и одной в правом верхнем углу.
Сбор данных с помощью движения мыши
Для каждого ответа программа MouseTracker записывала положение мыши от начальной точки до нажатия кнопки. Поскольку записанные траектории имели разную длину, каждый моторный ответ был нормализован по времени, чтобы можно было усреднить и сравнить испытания [25]. Используя линейную интерполяцию, программа рассчитала временную нормализацию в 101 таймфрейме. В результате каждая траектория имела 101 таймфрейм, и каждый таймфрейм имел соответствующие координаты X и Y.Мы определили момент времени, в который две группы показали максимальную разницу во время движения по оси ординат. Эти точки максимальной разницы во времени были закодированы как Y18, Y29 и Y30 (общее время было предварительно масштабировано до 100 временных кадров в соответствии с процедурой, утвержденной Freeman и Ambady [25]). Затем мы рассчитали скорость и ускорение в этих временных рамках. MouseTracker Программа по умолчанию записывает также другие пространственные и временные параметры. Здесь мы сообщаем обо всех параметрах, предварительно собранных программой MouseTracker и использованных для кодирования траектории мыши.Параметры, собранные из моторных ответов на каждый из вопросов, были следующими:
Используя линейную интерполяцию, программа рассчитала временную нормализацию в 101 таймфрейме. В результате каждая траектория имела 101 таймфрейм, и каждый таймфрейм имел соответствующие координаты X и Y.Мы определили момент времени, в который две группы показали максимальную разницу во время движения по оси ординат. Эти точки максимальной разницы во времени были закодированы как Y18, Y29 и Y30 (общее время было предварительно масштабировано до 100 временных кадров в соответствии с процедурой, утвержденной Freeman и Ambady [25]). Затем мы рассчитали скорость и ускорение в этих временных рамках. MouseTracker Программа по умолчанию записывает также другие пространственные и временные параметры. Здесь мы сообщаем обо всех параметрах, предварительно собранных программой MouseTracker и использованных для кодирования траектории мыши.Параметры, собранные из моторных ответов на каждый из вопросов, были следующими:
- Количество ошибок: общее количество ошибок при ответе на 32 вопроса
- Время инициации (IT): время между появлением вопроса и началом движения мыши
- Время реакции (RT): время между появлением вопроса и виртуальным нажатием кнопки с помощью мыши
- Максимальное отклонение (MD): максимальное перпендикулярное расстояние между фактической траекторией и идеальной траекторией (линия, соединяющая кнопку запуска с кнопкой ожидаемого ответа)
- Площадь под кривой (AUC): геометрическая площадь, заключенная между фактической траекторией и идеальной траекторией
- Максимальное время отклонения (MD-время): время, необходимое для достижения точки максимального отклонения от идеальной траектории
- x-flip: общее количество изменений направления мыши во время полной траектории по оси x
- y-flip: общее количество изменений направления мыши во время полной траектории по оси y
- Координаты X, Y во времени (X n , Y n ): положение мыши вдоль оси во времени
- Скорость во времени: скорость мыши между двумя временными рамками
- Ускорение во времени: ускорение движения мыши между двумя временными рамками
Окончательный список возможных предикторов включал 13 переменных, которые отображали различные параметры ответа: количество ошибок, время инициирования (IT), время реакции (RT), максимальное отклонение (MD), площадь под кривой (AUC). , Максимальное время отклонения (MD-время), x-flip, y-flip, Y30, Y29, Y18, Y30 – Y29 и Y29 – Y18.Для каждой из переменных мы вычислили среднее значение 32 ответов для каждого участника.
, Максимальное время отклонения (MD-время), x-flip, y-flip, Y30, Y29, Y18, Y30 – Y29 и Y29 – Y18.Для каждой из переменных мы вычислили среднее значение 32 ответов для каждого участника.
Корреляционный анализ и выбор признаков
Был проведен корреляционный анализ, чтобы выделить независимые переменные, которые имели максимальную корреляцию с зависимой переменной (правдивые против лжецов) и минимальную корреляцию между независимыми переменными [26]. Мы рассмотрели для каждой характеристики среднее значение всех ответов (ДА и НЕТ) каждого испытуемого.Всего в корреляционный анализ было введено 13 независимых переменных. Следующие характеристики были выбраны на основе этих критериев и позже использованы в качестве предикторов для разработки классификаторов машинного обучения (ML): количество ошибок (r pb = 0,68), AUC (r pb = 0,53), MD- времени (r pb = 0,45) и Y29 (r pb = 0,42) (r pb — значение корреляции между зависимыми и независимыми переменными).
Анализ и результаты
В этом разделе описаны шаги, выполняемые для анализа данных, и процедуры, использованные при разработке классификаторов машинного обучения.
Данные и инструкции по воспроизведению результатов доступны в качестве вспомогательной информации (см. Наборы данных S1 и S2, текст S1 и S2).
Анализ траекторий
Первый анализ сравнивал ответы лжецов и рассказчиков правды путем усреднения индивидуальных ответов на ответы ДА и НЕТ. На рис. 1 представлены средние траектории лжецов и правдивых, отвечающих ДА на ожидаемые и неожиданные вопросы (единственные вопросы, на которые лжецы отвечали лживо).Как можно заметить, две экспериментальные группы различались как по параметрам AUC, так и по MD. Ответы правдивых привели к более прямой траектории, соединяющей отправную точку с правильным ответом. Напротив, лжецы сначала отклонились в сторону правильного ответа по умолчанию, а затем изменили траекторию, чтобы нажать кнопку ложного ответа. Более того, лжецы тратили больше времени на перемещение по оси Y в начальной фазе ответа, чем те, кто говорил правду. Максимальная разница между двумя группами в положении мыши по оси Y была обнаружена на временном интервале 29.Соответственно, координата Y на этом временном интервале (Y29) также была добавлена в качестве предиктора.
Более того, лжецы тратили больше времени на перемещение по оси Y в начальной фазе ответа, чем те, кто говорил правду. Максимальная разница между двумя группами в положении мыши по оси Y была обнаружена на временном интервале 29.Соответственно, координата Y на этом временном интервале (Y29) также была добавлена в качестве предиктора.
Рис. 1. Средние траектории лжецов и правдивых.
На рисунке представлены средние траектории между испытуемыми, соответственно, для лжецов (красным) и для рассказчиков правды (зеленым) до ожидаемых ДА и неожиданных ДА вопросов. Ожидаемые и неожиданные вопросы, требующие ответа ДА, — это те, на которые лгали лжецы. Приведены значения параметров MD, AUC, x-flip и y-flip для двух групп.Серая область представляет собой разницу в параметре AUC между лжецами и правдивыми.
https://doi.org/10.1371/journal.pone.0177851.g001
Прототипные траектории правдивых и лжецов.
Здесь мы приводим примеры индивидуальных траекторий мыши в ответ на контрольные вопросы и неожиданные вопросы, полученные от прототипа рассказчика правды (рис. 2) и прототипа лжеца (рис. 3).
2) и прототипа лжеца (рис. 3).
Траектории относятся к ответам на отдельные вопросы.Обратите внимание, что этот лжец правдиво отвечает на контрольные вопросы. Тем не менее, его ответ отклоняется от прямой траектории, которая в идеале характеризует правдивый ответ (см. Рис. 2). Это обобщение мышления лжеца, когда лжец отвечает на вопросы, требующие правдивых ответов, обсуждается в статье.
Разбивка ответов на контрольные, ожидаемые и неожиданные вопросы.
Мы проанализировали выступления испытуемых отдельно для контрольных, ожидаемых и неожиданных вопросов.На рис. 4 представлена траектория контрольных, ожидаемых и неожиданных вопросов (слева направо). Траектории лжецов и правдивых в контрольных вопросах практически совпадают. Максимальная разница в траектории снова наблюдается в ответ на неожиданные вопросы.
Разбивка ответов ДА и НЕТ.
Мы исследовали, есть ли разница в траектории и времени ответа между вопросами, на которые испытуемые отвечали, перемещая мышь вправо (вопросы, не требующие ответа), и вопросами, на которые испытуемые отвечали, перемещая мышь влево ( вопросы, требующие ответа ДА). Тесты t по всей выборке были проведены для сравнения левого и правого откликов. Мы не обнаружили статистически значимой разницы как для времени MD ( t = 1,63; p = 0,1; Коэна d = 0,2; BF = 0,57) и Y29 ( t = 0,1; p = 0,9; Коэна d = 0,01; BF = 0,17). Для AUC мы получили следующие результаты: t = -2,09 и p = 0,04, но значение Коэна d показало небольшой размер эффекта ( d = -0.33), и фактор Байеса приблизился (BF = 1,2). На рис. 5 показаны траектории левого (зеленый) и правого (красный) ответов. Можно отметить, что две кривые следуют очень похожей, хотя и зеркальной, траектории.
Тесты t по всей выборке были проведены для сравнения левого и правого откликов. Мы не обнаружили статистически значимой разницы как для времени MD ( t = 1,63; p = 0,1; Коэна d = 0,2; BF = 0,57) и Y29 ( t = 0,1; p = 0,9; Коэна d = 0,01; BF = 0,17). Для AUC мы получили следующие результаты: t = -2,09 и p = 0,04, но значение Коэна d показало небольшой размер эффекта ( d = -0.33), и фактор Байеса приблизился (BF = 1,2). На рис. 5 показаны траектории левого (зеленый) и правого (красный) ответов. Можно отметить, что две кривые следуют очень похожей, хотя и зеркальной, траектории.
Рис. 5. Траектории ответов ДА и НЕТ.
Ответы на левую кнопку ответа и на правую кнопку ответа сообщаются здесь отдельно. Траектории двух типов ответов не различались.
https://doi.org/10.1371 / journal.pone.0177851.g005
Описательная статистика независимых переменных
Отдельный выбор признаков из исходного набора из 13 предикторов, 4 независимых переменных: ошибки, AUC, MD-время и Y29.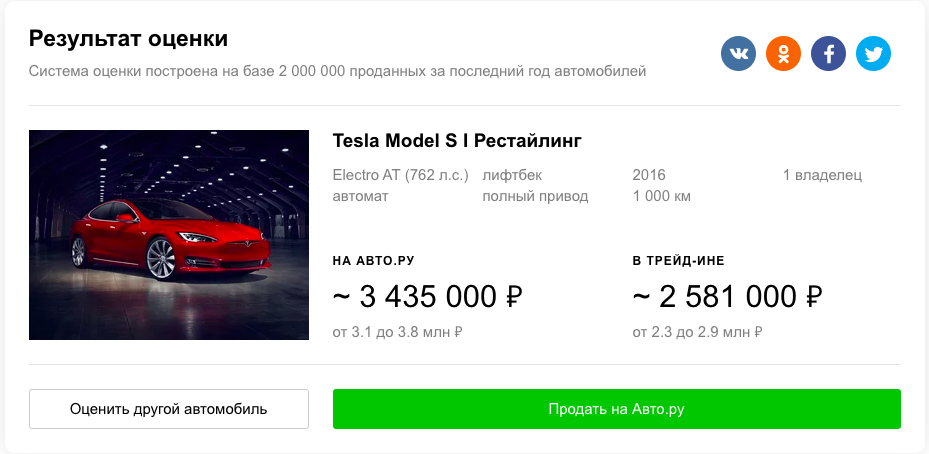 Они сильно коррелировали с группой (рассказчик правды / лжец). В следующей таблице (см. Таблицу 3) представлена описательная статистика, а также анализ разницы между правдивыми и лжецами, продемонстрированный с помощью t -теста, d Коэна и байесовского фактора.
Они сильно коррелировали с группой (рассказчик правды / лжец). В следующей таблице (см. Таблицу 3) представлена описательная статистика, а также анализ разницы между правдивыми и лжецами, продемонстрированный с помощью t -теста, d Коэна и байесовского фактора.
Модели машинного обучения
Несколько классификаторов машинного обучения (ML) были протестированы с использованием 10-кратной процедуры перекрестной проверки, реализованной WEKA [27]. Мы выбрали четыре классификатора, которые различаются в зависимости от своих предположений: Random Forest [28], Logistic [29], Support Vector Machine (SVM) [30–31] и Logistic Model Tree (LMT) [32]. 10-кратная перекрестная проверка проводилась следующим образом: группа участников (40 человек) была случайным образом разделена на 10 подгрупп по 4 человека в каждой.В каждом прогоне одна из 10 подвыборок сохранялась в качестве тестового набора для оценки модели, а оставшиеся 9 использовались в качестве обучающих данных. Затем процесс перекрестной проверки был повторен 10 раз, так что каждая из 10 подгрупп участников использовалась ровно 1 раз в качестве набора для проверки. Затем 10 результатов на тестовой выборке были усреднены для получения единственной оценки точности. Результаты представлены в таблице 4. Все классификаторы достигли точности около 90% или выше при классификации лжецов и правдивых.Как минимум 36/40 субъектов были правильно классифицированы. Логистический классификатор достиг точности 95% (правильно классифицировано 38/40 участников). Сопоставимые результаты были получены с использованием перекрестной проверки с исключением по одному (LOOCV) [33].
Затем процесс перекрестной проверки был повторен 10 раз, так что каждая из 10 подгрупп участников использовалась ровно 1 раз в качестве набора для проверки. Затем 10 результатов на тестовой выборке были усреднены для получения единственной оценки точности. Результаты представлены в таблице 4. Все классификаторы достигли точности около 90% или выше при классификации лжецов и правдивых.Как минимум 36/40 субъектов были правильно классифицированы. Логистический классификатор достиг точности 95% (правильно классифицировано 38/40 участников). Сопоставимые результаты были получены с использованием перекрестной проверки с исключением по одному (LOOCV) [33].
Как показано в таблице 5, модели классификации обладают высокой специфичностью и высокой чувствительностью. Фактически, в контрольных выборках ошибки классификации равномерно распределены по двум классам.
Оценка модели: выступление 20 итальянских участников вне выборки.
После разработки описанных выше классификаторов машинного обучения была собрана и протестирована дополнительная выборка из 20 участников (10 лжецов и 10 рассказчиков правды) с использованием моделей, ранее разработанных на основе исходных 40 участников. Эта группа участников была совершенно новой группой, которую раньше никогда не использовали для анализа или построения моделей. Эта процедура считается оптимальной стратегией, позволяющей избежать переобучения (см. Дворк и др. [34]). Точность классификации этого нового образца представлена в таблице 4.Стоит отметить, что точность классификации оставалась стабильной, в том числе по всем классификаторам, даже в этой проверочной выборке.
Эта группа участников была совершенно новой группой, которую раньше никогда не использовали для анализа или построения моделей. Эта процедура считается оптимальной стратегией, позволяющей избежать переобучения (см. Дворк и др. [34]). Точность классификации этого нового образца представлена в таблице 4.Стоит отметить, что точность классификации оставалась стабильной, в том числе по всем классификаторам, даже в этой проверочной выборке.
Вклад контрольных, ожидаемых и неожиданных вопросов.
Чтобы лучше понять вклад контрольных, ожидаемых и неожиданных вопросов в классификацию, мы использовали три отдельные модели для каждого типа вопросов. Результаты показывают, что основной вклад вносят неожиданные вопросы (см. Таблицу 6). Точность классификации с использованием классификаторов ML подтверждает, что невозможно эффективно отличить лжецов от правдивых только на основе контрольных вопросов.То же самое верно и для ожидаемых вопросов, хотя в этом случае траектории двух групп кажутся более разделенными (см. Рис. 4). Используя только неожиданные вопросы, точность классификации достигает максимума с показателями выше 90%, также в проверочной выборке, подтверждая, что когнитивная нагрузка лжецов из-за неожиданных вопросов является причиной различий между двумя группами.
Рис. 4). Используя только неожиданные вопросы, точность классификации достигает максимума с показателями выше 90%, также в проверочной выборке, подтверждая, что когнитивная нагрузка лжецов из-за неожиданных вопросов является причиной различий между двумя группами.
Относительный вес предикторов.
Мы также исследовали относительный вес предикторов, удаляя независимые переменные одну за другой и повторно прогоняя классификаторы.Результаты показали, что после устранения ошибок предикторов точность классификации упала примерно до 75% для перекрестной проверки и примерно до 70% для процедуры тестирования (случайный лес: перекрестная проверка = 70%, тест = 65%; логистическая : перекрестная проверка = 77,5%, проверка = 70%; SVM: перекрестная проверка = 75%, проверка = 65%; LMT: перекрестная проверка = 75%, проверка = 70%). Главный вклад в точность прогнозов вносится выявлением ошибок на неожиданные вопросы с помощью динамических функций мыши, тонко настраивающих и без того хорошую классификацию. Это ясно, если учесть, что прогнозы, основанные исключительно на ошибках, дали следующие результаты: Случайный лес: перекрестная проверка = 77,5%, тест = 100%; Логистика: перекрестная проверка = 82,5%, тест = 100%; SVM: перекрестная проверка = 80%, тест = 95%; LMT: перекрестная проверка = 85%; Тест = 100%. После удаления AUC из предикторов точность классификации осталась стабильной в тестовом наборе и упала до 90% во время перекрестной проверки (случайный лес: перекрестная проверка = 90%, тест = 95%; логистика: перекрестная проверка = 95%, test = 95%; SVM: перекрестная проверка = 85%, проверка = 95%; LMT: перекрестная проверка = 90%, проверка = 100%).Аналогичные результаты были получены при удалении MD-времени из предикторов (Случайный лес: перекрестная проверка = 90%, тест = 95%; Логистика: перекрестная проверка = 90%, тест = 95%; SVM: перекрестная проверка = 87,5%. , тест = 85%; LMT: перекрестная проверка = 90%, тест = 95%). Наконец, после выгрузки Y29 из предикторов точность как в обучающем, так и в тестовом наборах немного снизилась (Случайный лес: перекрестная проверка = 92,5%, тест = 95%; Логистика: перекрестная проверка = 95%, тест = 95%. ; SVM: перекрестная проверка = 92.5%, тест = 85%; LMT: перекрестная проверка = 92,5%, тест = 95%).
; SVM: перекрестная проверка = 92.5%, тест = 85%; LMT: перекрестная проверка = 92,5%, тест = 95%).
Вкратце, относительная важность независимых переменных показала, что общее количество ошибок дало основной вклад в правильное различение лжецов от правдивых, за которым следовали MD-время, AUC и положение мыши по оси y. ось на временном интервале 29 -го .
Анализ ошибок.
Ошибки для контроля и ожидаемые вопросы у лиц, говорящих правду, практически отсутствуют (см. Таблицу 7).В ответ на неожиданные вопросы чаще всего ошибались лжецы и рассказчики правды. Средний лжец делает в 12,4 раза больше ошибок при ответе на неожиданные вопросы по сравнению с правдивыми.
Лжецы и рассказчики правды не делают ошибок при проверке вопросов, а всего 2/240 на ожидаемые вопросы. Разница между этими двумя группами возникает из-за неожиданных вопросов, когда правдивые люди делают в общей сложности 5/240 ошибок, а лжецы — 82/240. Это указывает на то, что на каждую ошибку, допущенную правдой в ответ на неожиданные вопросы, лжецы делают 16 ошибок. Стоит отметить, что лжецы делают больше ошибок из-за неожиданного ДА (60/120, где они лгут), чем из-за неожиданного НЕТ (22/120, когда они отвечают правдиво), t = — 4,59, p <0,01; Коэна d = 1,60; BF = 16,42.
Немецкий проверочный образец.
Чтобы проверить, может ли модель эффективно классифицировать участников из разных культур, мы протестировали 20 немецких субъектов (10 лжецов и 10 рассказчиков правды) с хорошими результатами. Чтобы рассмотреть влияние культуры на обобщение результатов, мы протестировали выборку из 20 участников, носителей немецкого языка в Дюссельдорфе (10 рассказчиков правды и 10 лжецов; средний возраст = 29.5 лет; мужчины = 9/20) с вопросами на немецком языке. Перед экспериментом участники дали информированное согласие. Результаты этой группы были оценены с использованием модели, первоначально обученной на 40 итальянских участниках. Точность классификации была следующей: случайный лес = 95%, логистика = 100%, SVM = 90%, LMT = 95%. Анализ ошибок (см. Таблицу 8) показывает, что доля ошибок у лжецов и лиц, говорящих правду, сопоставима в двух группах (итальянский n = 40 и немецкий n = 20) с результатами для лжецов t = — 1.4, p = 0,17 ( d Коэна = -0,49, BF = 0,64) и результаты для правдивых t = 0,66, p = 0,52 ( d Коэна = 0,28, BF = 0,43) .
Анализ ошибок (см. Таблицу 8) показывает, что доля ошибок у лжецов и лиц, говорящих правду, сопоставима в двух группах (итальянский n = 40 и немецкий n = 20) с результатами для лжецов t = — 1.4, p = 0,17 ( d Коэна = -0,49, BF = 0,64) и результаты для правдивых t = 0,66, p = 0,52 ( d Коэна = 0,28, BF = 0,43) .
Можем ли мы обнаружить лжецов, если они отвечают правдиво?
Схема эксперимента, описанная в рукописи, требует, чтобы лжецы лгали только тогда, когда отвечали ДА на ожидаемые и неожиданные вопросы ДА. Во всех остальных условиях (ожидаемое НЕТ, неожиданное НЕТ, контрольный ДА и контрольный вопрос НЕТ) лжецы отвечали правдиво (см. Таблицу 2).Интересный вопрос: можно ли обнаружить лжецов по их правдивым ответам? В предыдущем разделе мы сравнили траектории ответов двух групп с ожидаемыми и неожиданными вопросами, на которые требовался ответ ДА (см. Рис. 1). Здесь мы сравнили траектории двух групп для ответов, требующих ответа НЕТ, и для всех контрольных вопросов. Траектории, когда лжецы отвечали правдиво, показаны на рис. 6. Хотя разница уменьшается по сравнению с ответами, в которых лжецы лгали, различия с рассказчиками правды все же заметны.
Траектории, когда лжецы отвечали правдиво, показаны на рис. 6. Хотя разница уменьшается по сравнению с ответами, в которых лжецы лгали, различия с рассказчиками правды все же заметны.
Рис. 6. Траектории, когда лжецы ответили правдиво.
На этом рисунке показаны средние траектории ответов на вопросы, на которые правдиво ответили как лжецы (красным), так и правдивые (зеленым).
https://doi.org/10.1371/journal.pone.0177851.g006
Чтобы оценить, отличались ли траектории лжецов и тех, кто говорил правду, когда они не лгали, мы сравнили две экспериментальные группы. о независимых переменных, ранее использовавшихся при разработке классификаторов.Результаты независимого t-теста, представленные в таблице 9, показывают, что стили ответа лжецов могут быть идентифицированы, даже если лжецы отвечали правдиво. Классификаторы имели следующие уровни точности при идентификации лжецов и правдивых только на основе ответов на вопросы, на которые лжецы отвечали правдиво: случайный лес = 77,5%, SVM = 80%, логистика = 80% и LMT = 77,5%. Очевидно, что все классификаторы были относительно точными, даже если они были ниже точности классификации, основанной только на ответах ДА на ожидаемые и неожиданные вопросы (что находилось в диапазоне 90–92%).
Очевидно, что все классификаторы были относительно точными, даже если они были ниже точности классификации, основанной только на ответах ДА на ожидаемые и неожиданные вопросы (что находилось в диапазоне 90–92%).
Как статистический анализ, так и анализ машинного обучения показали, что признаки лжи распространяются на вопросы, на которые они правдиво ответили. Даже если отвечать правдиво, лжецов можно идентифицировать, но с меньшей точностью. С когнитивной точки зрения здесь интересно то, что в плане эксперимента мышление лжецов также распространило свои эффекты на вопросы, когда они отвечали правдиво. Насколько нам известно, такая картина результатов никогда ранее не сообщалась и может указывать на уровень чувствительности метода анализа движения мыши.
Обсуждение
Насколько нам известно, никакие методы не могут точно определить, является ли идентификатор субъекта истинным или ложным без какой-либо информации об истинной личности респондента. В этой статье мы сообщаем о результатах нового метода обнаружения памяти, нацеленного на определение того, является ли идентификатор истинным или поддельным, когда лжецы не предоставляют никакой личной информации, которая затем включается в сам тест.
Участники отвечали с помощью мыши на вопросы, касающиеся идентификатора, на которые требовался ответ ДА / НЕТ.Динамика мыши предоставляет богатый источник данных по сравнению с аналогичными задачами двоичной классификации, основанными на кнопках ответа. Хотя данные, собранные при нажатии кнопок, ограничиваются записью задержки между началом вопроса и нажатием кнопки, реакция мыши позволяет собирать несколько параметров, включая время реакции, а также время начала, скорость, ускорение и траекторию мыши.
Чтобы разработать модель, которая эффективно выявляет участников с поддельными именами, мы протестировали респондентов с вопросами, которые ожидались и которые лжецы усвоили на этапе предварительного обучения (имя, фамилия, дата рождения и место рождения).Наряду с ожидаемыми вопросами, касающимися информации документа, удостоверяющего личность, также был представлен ряд неожиданных вопросов, связанных с ожидаемыми вопросами. Рассмотрим, например, место рождения. Ожидаемые вопросы, которые появятся в удостоверении личности, будут: «Вы родились в Пизе?» (требуется ответ ДА) или «Вы родились в Нью-Йорке?» (требуя ответа НЕТ). Соответствующие неожиданные вопросы будут такими: «Флоренция — столица региона, в котором вы родились?» (требуется ответ ДА, учитывая, что Пиза, место рождения, находится в Тоскане, столицей которой является Флоренция) и «Является ли Венеция столицей региона вашего рождения?» (не требуя ответа, учитывая, что Пиза, заявленное место рождения, находится в Тоскане, столицей которой является Флоренция, а не Венеция).Еще один неожиданный вопрос, связанный с датой рождения (производной от даты), касался зодиака. Говорящие правду должны иметь возможность получать ответы об их истинном зодиаке более автоматически, чем лжецы; поэтому ожидается, что их ответ будет более быстрым, с меньшим количеством ошибок и будет характеризоваться более прямой траекторией движения мыши. В целом, неожиданные вопросы должны быть быстро найдены рассказчиками правды, в то время как лжецы должны мысленно «вычислить» ответ на основе исходной ожидаемой информации [21].
Соответствующие неожиданные вопросы будут такими: «Флоренция — столица региона, в котором вы родились?» (требуется ответ ДА, учитывая, что Пиза, место рождения, находится в Тоскане, столицей которой является Флоренция) и «Является ли Венеция столицей региона вашего рождения?» (не требуя ответа, учитывая, что Пиза, заявленное место рождения, находится в Тоскане, столицей которой является Флоренция, а не Венеция).Еще один неожиданный вопрос, связанный с датой рождения (производной от даты), касался зодиака. Говорящие правду должны иметь возможность получать ответы об их истинном зодиаке более автоматически, чем лжецы; поэтому ожидается, что их ответ будет более быстрым, с меньшим количеством ошибок и будет характеризоваться более прямой траекторией движения мыши. В целом, неожиданные вопросы должны быть быстро найдены рассказчиками правды, в то время как лжецы должны мысленно «вычислить» ответ на основе исходной ожидаемой информации [21].
Исследование, представленное здесь, продемонстрировало, что динамика мыши, проанализированная с использованием модели машинного обучения, дала правильную классификацию лжецов и рассказчиков правды с точностью более 90%. Этот результат был достигнут путем разработки набора классификаторов с сопоставимой производительностью в диапазоне точности 90–95% (Random Forest, SVM, Logistics и LTM). Другая группа была собрана и протестирована (10 рассказчиков правды и 10 лжецов) для проверки обобщения модели. В этой группе было подтверждено, что точность сопоставима с точностью группы, использованной для разработки классификаторов (95% = 19/20 участников правильно классифицированы), что показывает, что высокая точность, достигнутая на этапе построения модели, не была результатом переоснащение.
Этот результат был достигнут путем разработки набора классификаторов с сопоставимой производительностью в диапазоне точности 90–95% (Random Forest, SVM, Logistics и LTM). Другая группа была собрана и протестирована (10 рассказчиков правды и 10 лжецов) для проверки обобщения модели. В этой группе было подтверждено, что точность сопоставима с точностью группы, использованной для разработки классификаторов (95% = 19/20 участников правильно классифицированы), что показывает, что высокая точность, достигнутая на этапе построения модели, не была результатом переоснащение.
Теория игр также является многообещающим методом в глубоком обучении. Мы не оценивали, могут ли более сложные модели глубокого обучения, основанные на концепциях теории игр [35–37], превзойти стандартные модели машинного обучения, которые мы использовали в этом исследовании, но это может стать будущим направлением.
Мы провели анализ для определения наиболее важного предиктора, которым были общие ошибки, за которыми следовали MD-время, AUC и положение мыши по оси Y на временном кадре 29 -го .
С когнитивной точки зрения подтверждено, что неожиданные вопросы могут использоваться для раскрытия обмана. Сила неожиданных вопросов широко исследовалась на следственных допросах [22]. Здесь мы расширяем результаты и подтверждаем, что неожиданные вопросы могут быть встроены в тест проверки личности, чтобы позволить идентифицировать лиц, вводящих в заблуждение, с высокой точностью. Лжецам трудно отвечать на неожиданные вопросы быстро и без ошибок. Их неуверенность улавливается динамикой мыши, поскольку их двигательное поведение отклоняется от идеальной траектории говорящего правду.
Интересно отметить, что наш экспериментальный план требует от лжецов правдивых ответов на ряд вопросов. Анализ таких правдивых ответов показывает, что лжецов по-прежнему можно обнаружить, даже с меньшей точностью, если они не лгут. Розенфельд и др. показали, что лжецов, говорящих правду, можно идентифицировать с помощью P300, аналогично тому, о чем мы сообщаем здесь [38]. Важно отметить, что лжецы должны честно отвечать на все стимулы, кроме ожидаемых и неожиданных вопросов, которые, напротив, требуют лжи. Следовательно, они должны переключаться между ложью и правдой, и этот переход имеет цену, которая проявляется также при правдивом ответе, как показали Деби и др. [39]. Это означает, что образ мышления лжеца отражается в динамике мыши, и что обнаружение лжи можно также распространить на ответы, которым они не лгут. Это как если бы инструкция лгать на одни вопросы, но не на другие, вызывает у лжецов большую когнитивную нагрузку, которая связана не только с обманчивыми ответами, но и с переключением между ответами, требующими лжи, и ответами, требующими правды.
Неожиданные вопросы требуют тщательной подготовки ответов, и это может быть ограничением при автоматическом онлайн-использовании метода. Дальнейшие ограничения настоящего исследования включают тот факт, что процедура была протестирована на участниках одной культуры, а обобщение проверено на участниках, принадлежащих к другой культуре (Германия). Дальнейшее ограничение настоящего исследования проистекает из того факта, что проблема обнаружения поддельных удостоверений личности не позволяет проводить прямое сравнение с более проверенными методами обнаружения лжи (например,г. , ЦИТ). Таким образом, любое сравнение методов носит косвенный характер.
, ЦИТ). Таким образом, любое сравнение методов носит косвенный характер.
Принимая во внимание все эти ограничения, мы думаем, что использование неожиданных вопросов в сочетании с анализом динамики мыши кажется многообещающим путем для выявления обманчивых ответов.
Вклад авторов
- Концептуализация: GS MM.
- Обработка данных: MM.
- Формальный анализ: GS MM.
- Расследование: ММ.
- Методология: GS MM LG.
- Надзор: GS.
- Подтверждение: GS MM LG.
- Написание — черновик: MM GS.
- Написание — просмотр и редактирование: GS MM LG.
Ссылки
- 1. УЕФА. Встанет ли настоящий Эриберто. 20 сентября 2002 г. http://www.uefa.com/news/newsid=34451.html.
- 2.
Donath JS. Личность и обман в виртуальном сообществе.В: Смит М.А., Коллок П. редакторы. Сообщества в киберпространстве. Лондон и Нью-Йорк: Routledge Press; 1999. С. 29–59.
- 3. Барбер С. Прямая связь между кражей личных данных и терроризмом и способы ее остановить. Техасский университет в Остине. 7 декабря 2015 г. https://news.utexas.edu/2015/12/07/the-direct-link-between-identity-theft-and-terrorism
- 4. Agenzia Giornalistica Italia (AGI). Брюссель: камикадзе нас идентифицируют с бывшим giocatore dell’Inter. 28 марта 2016 г.http://www.agi.it/estero/2016/03/28/news/bruxelles_kamikaze_uso_identita_ex_giocatore_dellinter-650281/
- 5. Бенусси В. Die atmungssymptome der lüge. Archiv für die gesamte Psychologie. 1914; 31: 244–273.
- 6. Розенфельд JP, Грили ХТ. Обман, обнаружение, потенциал, связанный с событием p300 (erp). В: Энциклопедия судебной медицины Wiley. John Wiley & Sons, Ltd; 2009.
- 7.
Vrij A, Fisher R, Mann S, Leal S. Подход когнитивной нагрузки к обнаружению лжи.Психология расследования и профилирование преступников. 2008; 5: 39–43.
- 8. Ван Бокстаэле Б., Вершуере Б., Моенс Т., Сухоцки К., Деби Э., Спруит А. Научиться лгать: влияние практики на когнитивные издержки лжи. Границы психологии. 2012; 3: 526. pmid: 23226137
- 9. Кляйнберг Б., Вершуере Б. Обнаружение памяти 2.0: первый веб-тест на обнаружение памяти. PLoS One. 2015; 10 (4): e0118715. pmid: 25874966
- 10. Сартори Г., Агоста С., Зогмайстер С., Феррара С.Д., Кастиэльо Ю.Как точно определять автобиографические события. Психологическая наука. 2008. 19 (8): 772–780. pmid: 18816284
- 11.
Verschuere B, Kleinberg B. Идентификационная проверка: онлайн-проверка скрытой информации выявляет истинную личность. Журнал судебной медицины. 2016, январь; 61 Приложение 1: S237–40. pmid: 263
- 12.
Агоста С., Сартори Г. Автобиографический IAT: обзор. Границы психологии. 2013; 4: 519. pmid: 23964261
- 13. Meixner J, Rosenfeld JP. Имитация терроризма Применение теста скрытой информации на основе P300.Психофизиология. 2011. 48: 149–154. pmid: 20579312
- 14. Дейл Р., Дюран Н.Д. Когнитивная динамика верификации отрицательного предложения. Наука о мышлении. 2011; 35 (5): 983–996. pmid: 21463359
- 15. Фриман Дж. Б., Паукер К., Санчес Д. Т.. Перцептивный путь к предвзятости: межрасовое воздействие снижает резкие сдвиги в восприятии расы в реальном времени, которые предсказывают предвзятость смешанной расы. Психологическая наука. 2016; 27: 502–517. pmid: 26976082
- 16. Quétard B, Quinton JC, Colomb M, Pezzulo G, Barca L, Izaute M и др.Комбинированные эффекты ожидания и визуальной неопределенности при обнаружении и идентификации цели в тумане. Когнитивная обработка. 2015; 16: 343–348.
- 17.
Эбни Д.Х., Макбрайд Д.М., Конте А.М., Винсон Д.В. Динамика ответа в предполагаемой памяти. Психономический бюллетень и обзор. 2015; 22 (4): 1020–1028.
- 18. Барка Л., Пеццуло Г. Разворачивание визуального лексического решения во времени. PLoS One. 2012; 7 (4): e35932. pmid: 22563419
- 19. Дюран Н.Д., Дейл Р., Макнамара Д.С.Динамика действия преодоления истины. Психономический бюллетень и обзор. 2010. 17 (4): 486–491.
- 20. Врий А. Когнитивный подход к обнаружению лжи в обнаружении обмана: текущие проблемы и новые подходы. Оксфорд, Великобритания: John Wiley & Sons, Inc.; 2015.
- 21. Вридж А., Леал С., Гранхаг П.А., Манн С., Фишер Р.П., Хиллман Дж. И др. Перехитрить лжецов: польза от задания неожиданных вопросов. Закон и человеческое поведение. 2009. 33: 159–166. pmid: 18523881
- 22.Warmelink L, Vrij A, Mann S, Leal S, Poletiek FH. Влияние неожиданных вопросов на обнаружение знакомой и незнакомой лжи. Психиатрия, психология и право. 2013; 20 (1).
- 23.
Хартвиг М. , Гранхаг П.А., Стрчмвалл Л. Стратегии виновных и невиновных подозреваемых во время допросов. Психология, преступность и право. 2007. 13: 213–227.
- 24. Ланкастер Г.Л., Вридж А., Хоуп Л., Уоллер Б. Отделение лжецов от рассказчиков правды: преимущества задания непредвиденных вопросов об обнаружении лжи.Прикладная когнитивная психология. 2013; 27: 107–114.
- 25. Freeman JB, Ambady N. Mousetracker: Программное обеспечение для изучения умственной обработки в реальном времени с использованием метода компьютерного отслеживания мыши. Методы исследования поведения. 2010. 42: 226–241. pmid: 20160302
- 26. Зал МА. Выбор подмножества функций на основе корреляции для машинного обучения. Диссертация, Университет Вайкато. 1999. http://www.cs.waikato.ac.nz/mhall/thesis.pdf.
- 27.
Холл М., Фрэнк Э., Холмс Г., Пфарингер Б., Ройтеманн П., Виттен И.Программное обеспечение для интеллектуального анализа данных weka: обновление. Информационный бюллетень ACM SIGKDD Explorations. 2009. 11 (1): 10–18.
- 28. Брейман Л. Случайные леса. Машинное обучение. 2001. 45 (1): 5–32.
- 29. le Cessie S, van Houwelingen JC. Оценщики гребня в логистической регрессии. Прикладная статистика. 1992. 41 (1): 191–201.
- 30. Platt JC. Быстрое обучение опорных векторных машин с использованием последовательной минимальной оптимизации. В: Достижения в методах ядра. MIT Press Cambridge; 1999 г.
- 31. Кеэрти СС, Шеваде СК, ЦБ, Мурти КРК. Улучшения в алгоритме SMO Platt для проектирования классификатора SVM. Нейронные вычисления. 2001. 13 (3): 637–649.
- 32. Ландвер Н., Холл М., Фрэнк Э. Деревья логистических моделей. Машинное обучение. 2005. 95 (1–2): 161–205.
- 33.
Гао З.К., Цай Цюй, Ян YX, Донг Н, Чжан СС. График видимости из частотно-временного представления адаптивного оптимального ядра для классификации эпилептиформной ЭЭГ. Международный журнал нейронных систем.2017; 27 (4): 1750005. pmid: 27832712
- 34. Дворк С., Фельдман В., Хардт М., Питасси Т., Рейнгольд О., Рот А. Многоразовое удержание: сохранение достоверности в адаптивном анализе данных. Наука. 2015; 349: 636–638. pmid: 26250683
- 35. Ван Дж., Лу В., Лю Л., Ли Л., Ся К. Оценка полезности на основе однозначного сопоставления в игре «Дилемма заключенного для взаимозависимых сетей». PLoS ONE. 2016; 11 (12): e0167083. pmid: 274
- 36. Чен М., Ван Л., Сунь С., Ван Дж., Ся К.Эволюция сотрудничества в игре пространственных общественных благ с адаптивным ассортиментом репутации. Physics Letters A. 2016; 380 (1): 40–47.
- 37. Чен М., Ван Л., Ван Дж., Сунь С., Ся С. Влияние стратегии индивидуального реагирования на пространственную игру общественных благ внутри мобильных агентов. Прикладная математика и вычисления. 2015; 251: 192–202
- 38.
Розенфельд Дж. П., Элвангер Дж. В., Нолан К., Ву С., Берманн Р. Г., Свит Дж. Распределение амплитуды скальпа P300 как показатель обмана в модели имитируемого когнитивного дефицита.Международный журнал психофизиологии. 1999; 33 (1): 3–19. pmid: 10451015
- 39. Деби Э., Баптист Л.Б., де Хауэр Дж., Вершуер Б. Ложь, правда, ложь: роль переключения задач в контексте обмана. Психологическое психологическое исследование. 2015; 79 (3): 478–488.
 Личность и обман в виртуальном сообществе.В: Смит М.А., Коллок П. редакторы. Сообщества в киберпространстве. Лондон и Нью-Йорк: Routledge Press; 1999. С. 29–59.
Личность и обман в виртуальном сообществе.В: Смит М.А., Коллок П. редакторы. Сообщества в киберпространстве. Лондон и Нью-Йорк: Routledge Press; 1999. С. 29–59. 2013; 4: 519. pmid: 23964261
2013; 4: 519. pmid: 23964261 Психономический бюллетень и обзор. 2015; 22 (4): 1020–1028.
Психономический бюллетень и обзор. 2015; 22 (4): 1020–1028. , Гранхаг П.А., Стрчмвалл Л. Стратегии виновных и невиновных подозреваемых во время допросов. Психология, преступность и право. 2007. 13: 213–227.
, Гранхаг П.А., Стрчмвалл Л. Стратегии виновных и невиновных подозреваемых во время допросов. Психология, преступность и право. 2007. 13: 213–227. Международный журнал нейронных систем.2017; 27 (4): 1750005. pmid: 27832712
Международный журнал нейронных систем.2017; 27 (4): 1750005. pmid: 27832712 П., Элвангер Дж. В., Нолан К., Ву С., Берманн Р. Г., Свит Дж. Распределение амплитуды скальпа P300 как показатель обмана в модели имитируемого когнитивного дефицита.Международный журнал психофизиологии. 1999; 33 (1): 3–19. pmid: 10451015
П., Элвангер Дж. В., Нолан К., Ву С., Берманн Р. Г., Свит Дж. Распределение амплитуды скальпа P300 как показатель обмана в модели имитируемого когнитивного дефицита.Международный журнал психофизиологии. 1999; 33 (1): 3–19. pmid: 10451015satoshiiizuka / siggraph3016_colorization: Код для статьи «Да будет цвет!: Совместное сквозное изучение глобальных и локальных приоритетов изображения для автоматической раскраски изображения с одновременной классификацией».
Сатоши Иидзука *, Эдгар Симо-Серра *, Хироши Исикава (* равный вклад)
Обзор
Этот код обеспечивает реализацию исследовательской статьи:
«Да будет цвет!: Совместное сквозное изучение глобальных и локальных априоров изображений для автоматической окраски изображений с одновременной классификацией»
Сатоши Иидзука, Эдгар Симо-Серра и Хироши Исикава
ACM Transaction on Graphics (Proc. Of SIGGRAPH 2016), 2016 г.
 Of SIGGRAPH 2016), 2016 г.
Of SIGGRAPH 2016), 2016 г.
Мы учимся автоматически раскрашивать полутоновые изображения с помощью глубокой сети.Наш сеть изучает как локальные, так и глобальные особенности вместе в одном рамки. Затем наш подход можно использовать для изображений любого разрешения. К Включая глобальные функции, мы можем получить реалистичные цвета с наша модель.
См. Страницу нашего проекта для более подробной информации.
Лицензия
Copyright (C) <2016> <Сатоши Иидзука, Эдгар Симо-Серра, Хироши Исикава>
Эта работа находится под лицензией Creative Commons
Attribution-NonCommercial-ShareAlike 4.0 Международная лицензия. Для просмотра копии
этой лицензии посетите http://creativecommons.org/licenses/by-nc-sa/4.0/ или
отправьте письмо по адресу Creative Commons, PO Box 1866, Mountain View, CA 94042, США.
Сатоши Иидзука, Университет Васэда
[email protected], http://hi.cs.waseda.ac.jp/~iizuka/index_eng.html
Эдгар Симо-Серра, Университет Васеда
esimo@aoni. waseda.jp, http://hi.cs.waseda.ac.jp/~esimo/
 waseda.jp, http://hi.cs.waseda.ac.jp/~esimo/
waseda.jp, http://hi.cs.waseda.ac.jp/~esimo/
Зависимости
Все пакеты должны быть частью стандартной установки Torch7.Для получения информации о том, как установить Torch7, обратитесь к официальной документации по факсу по данной теме.
Использование
Сначала загрузите модель раскраски, запустив сценарий загрузки:
./download_model.sh
Базовое использование:
th colorize.lua []
Например:
-й colorize.lua ansel_colorado_1941.png out.png
Лучшая производительность
- Эта модель была обучена на наборе данных Places, поэтому наилучшая производительность для естественных изображений на открытом воздухе.
- Хотя модель работает с изображениями любого размера, мы обучили ее на изображениях 224x224 пикселей, поэтому она лучше всего работает с небольшими изображениями. Обратите внимание, что вы можете обработать небольшое изображение, чтобы получить карту цветности, а затем изменить его масштаб и объединить с исходным изображением в градациях серого для более высокого качества.
- Изображение большего размера может давать неравномерную окраску (ограничено пространственной поддержкой сети).

Модель ImageNet
Мы также предоставляем модель раскрашивания, которая была обучена на ImageNet.Эту модель можно использовать для сравнения с другими моделями раскрашивания, обученными в ImageNet. Мы рекомендуем использовать модель раскраски мест для общих целей.
Для использования модели ImageNet загрузите модель, запустив:
./download_model_imagenet.sh
Использование:
th colorize.lua colornet_imagenet.t7
Банкноты
- Он разработан на Linux-машине под управлением Ubuntu 14.04 в конце 2015 года.
- В предоставленном коде не используется ускорение графического процессора (легко изменить).
- Обратите внимание, что модель работает медленно с большими изображениями (более 512x512 пикселей) и может не хватить памяти. Демонстрационная версия должна занимать около 2 ГиБ максимальной оперативной памяти, рекомендуется система с 4 ГиБ или более ОЗУ.
- Предоставленная модель и образец кода находятся под некоммерческой лицензией Creative Commons.
 Демонстрационная версия должна занимать около 2 ГиБ максимальной оперативной памяти, рекомендуется система с 4 ГиБ или более ОЗУ.
Демонстрационная версия должна занимать около 2 ГиБ максимальной оперативной памяти, рекомендуется система с 4 ГиБ или более ОЗУ.Цитирование
Если вы используете этот код, укажите:
@Article {IizukaSIGGRAPh3016,
author = {Сатоши Иидзука, Эдгар Симо-Серра и Хироши Исикава},
title = {{Да будет цвет !: Совместное сквозное изучение глобальных и локальных приоритетов изображения для автоматической раскраски изображения с одновременной классификацией}},
journal = "Транзакции ACM по графике (Proc.СИГГРАФА 2016) »,
год = 2016,
объем = 35,
число = 4,
}
Ради фокуса !: Справочник округа 32 по ирландскому сленгу (Irish Slang Books) (9780955475528): Фоли, мистер Киан: Книги
.a-tab-content> .a-box-inner {padding-top: 5px; padding-bottom: 5 пикселей; } #mediaTabs_tabSetContainer . a-tab-content {border-radius: 0px; }
#mediaTabsHeadings {white-space: nowrap; переполнение: скрыто; }
#mediaTabsHeadings.nonJSTabs {пробел: нормальный; }
#mediaTabsHeadings ul.a-tabs {background: # f9f9f9; }
#mediaTabsHeadings .mediaTab_heading .mediaTab_logo {padding-left: 3px; вертикальное выравнивание: базовая линия; }
#mediaTabsHeadings #mediaTabs_tabSet {margin-top: 5px; плыть налево; граница справа: 0 пикселей; }
#mediaTabsHeadings .mediaTab_heading {margin-left: -1px; }
#mediaTabsHeadings .mediaTab_heading a {color: # 111; граница справа: сплошной 1px #ddd; padding-top: 8 пикселей; padding-bottom: 7 пикселей; }
#mediaTabsHeadings .mediaTab_heading.a-active a {color: # c45500; маржа сверху: -5 пикселей; padding-top: 11 пикселей; граница слева: сплошной 1px #ddd; border-top-width: 3px;}
#mediaTabsHeadings .tabHidden {display: none! important; }
#bookDescription_feature_div {дисплей: встроенный блок; ширина: 100%;}
]]>
a-tab-content {border-radius: 0px; }
#mediaTabsHeadings {white-space: nowrap; переполнение: скрыто; }
#mediaTabsHeadings.nonJSTabs {пробел: нормальный; }
#mediaTabsHeadings ul.a-tabs {background: # f9f9f9; }
#mediaTabsHeadings .mediaTab_heading .mediaTab_logo {padding-left: 3px; вертикальное выравнивание: базовая линия; }
#mediaTabsHeadings #mediaTabs_tabSet {margin-top: 5px; плыть налево; граница справа: 0 пикселей; }
#mediaTabsHeadings .mediaTab_heading {margin-left: -1px; }
#mediaTabsHeadings .mediaTab_heading a {color: # 111; граница справа: сплошной 1px #ddd; padding-top: 8 пикселей; padding-bottom: 7 пикселей; }
#mediaTabsHeadings .mediaTab_heading.a-active a {color: # c45500; маржа сверху: -5 пикселей; padding-top: 11 пикселей; граница слева: сплошной 1px #ddd; border-top-width: 3px;}
#mediaTabsHeadings .tabHidden {display: none! important; }
#bookDescription_feature_div {дисплей: встроенный блок; ширина: 100%;}
]]> Доставка и продажа на Amazon. com.
com.

EFL | TEFL | Рабочие листы ESL, раздаточные материалы, планы уроков и ресурсы для учителей английского языка.
"Вы слишком много онлайн?" отлично подходит для развития у ваших учеников навыков чтения, лексики и обсуждения.
Ваши ученики приклеены к своему телефону? Смогут ли они выжить вдали от Facebook? В чем обратная сторона наличия всего в сети?
Этот рабочий лист содержит три коротких «vox-pop» чтения с построением словосочетания и обсуждением.Изучаемые выражения включают:
- быть зависимым от Интернета
- для отправки сообщения
- почувствовать облегчение
- старшее поколение
- ... и другие
Отлично подходит для классов ниже среднего. Для более высоких уровней ищите наш рабочий лист «Интернет-зависимость».
«Безмолвная Вселенная» рассматривает тему внеземной жизни - или, скорее, ее отсутствие.
Есть ли в космосе разумная инопланетная жизнь? Если да, то почему мы еще ничего не нашли?
Этот рабочий лист рассматривает «парадокс Ферми» - вопрос о том, почему, кажется, нет жизни за пределами этой планеты. Мы уникальны? Или есть какое-то соглашение, подобное «Звездному пути», чтобы не связываться с нами?
Какой бы ни была причина, это отличная тема для чтения и обсуждения. Ваши ученики выучат такие выражения, как:
- оглушительная тишина
- почти наверняка
- , чтобы нарисовать заготовку
- , чтобы изобиловать жизнью
- и другие.
С вводными упражнениями, упражнениями на словосочетание, прочтением пробелов и вопросами для обсуждения вашим ученикам есть во что вникнуть!
Этот рабочий лист предназначен для учащихся выше среднего и продвинутого уровня.
Также выпущен в этом месяце: наши чтения святого Валентина, рассказывающие об истоках Дня святого Валентина и различных способах его празднования во всем мире. Мы также внесли множество обновлений в рабочие листы, в том числе наш третий условный рабочий лист Изменения в удаче и расширенное чтение Беспилотные самолеты .
Чтобы увидеть наши новые рабочие листы, перейдите на нашу страницу «Новые рабочие листы».
Схема двигателя Chevy Monte Carlo 1999 года - схема подключения Сервер wood-match
Схема двигателя Chevy Monte Carlo 1999 года Что нового
Схема двигателя Chevrolet Monte Carlo 1999 года -1974 Схема электрических соединений Chevrolet Monte Carlo 564 kb 1977 1980 Chevrolet Truck small block Электрическая схема части двигателя v8 317 kb 1981 1987 Шевроле шасси и задняя схема 283 kb.Подробные характеристики и спецификации подержанного Chevrolet Monte Carlo 1999 года, включая гарантию экономии топлива на трансмиссию Тип двигателя cy nders трансмиссия и другие прочитайте отзывы просмотрите наш автомобиль p class grp grp talgo факты ul class pinfo mt 10 bxz bb d ib va top style max width 50 class tc bxz bb pr 24 lh 18 label class fw b 4 4 5 label class strs mr 2 class ico full strs mr full mt 1 class ico full strs mr full mt 1 class ico full strs mr full mt 1 class ico full strs mr full mt 1 класс ico half strs mr half mt 1 39 class tc bxz bb pr 24 lh 18 label class fw b mpg label 21 bined mpg ul ul class pinfo mt 10 bxz bb d ib va top style max width 50 class tc bxz bb pr 24 lh 18 этикетка класса fw b передняя этикетка трансмиссии.
1999 chevy monte carlo схема двигателя - полноприводный класс tc bxz bb pr 24 lh 18 label class fw b трансмиссионный ярлык 4-ступенчатая автоматическая ul class dd algo algo sr relsrch richalgo data 8e9 603e4668ebd78 параметры заголовка класса переключить h4 class title ov ha style ne height 1 3 class ac algo fz l ac 21th lh 24 href https r search Yahoo ylt awrj7frorj5gro0aiapxnyoa ylu y29sbwnizjeecg9zazmednrpzamec2vja3ny rv 2 re 1614722792 ro 10 ru https 3a target 2f8 2fen 2gen wik пустые данные 8e9 603e4668ebe68 chevrolet monte carlo wikipedia a h4 class fz ms fw m fc 12th wr bw lh 17 en wikipedia org wiki chevrolet monte carlo class tri ico стрелка вниз серый толстый optrg ul class pd nk параметры алгоритма hadnz 4 bgc белый bd 1 bds s bdc lgray1 bs type1 ptb 1u класс db selected class txt a class t1 c dgray c черный h bgc lgray3 hdb plr 3u ptb 1u td n td nh href.
1999 Chevy Монте-Карло-схема двигателя - HTTPS г поиск Yahoo уг awrj7frorj5gro0aiqpxnyoa ylu y29sbwnizjeecg9zazmednrpzamec2vja3ny с. в. 2 повторно 1614722792 ро 10 RU HTTPS 3a 2f 2fcc bingj 2fcache ASPX 3fq 3d1999 2bchevy 2bmonte 2bcarlo 2bengine 2bdiagram 26d 3d4854868008444750 26mkt 3den нас 26setlang 3den нам 26w 3do2crccqoeesfvuatw9bjb60refrlal6i rk 2 rs hsroj8fuiwvecizrpcywyvj4qjw referrerpo cy origin target пустой кэшированный файл. Заднеприводный личный роскошный автомобиль Chevrolet Monte Carlo Chevy 39 1985 года получил больше мощности, но впервые с 1981 года в Монте-Карло не предлагался дизельный двигатель на базовой модели. 4 3 л v6 с корпусом дроссельной заслонки впрыск топлива p class grp grp talgo факты ul class pinfo mt 10 bxz bb d ib va top style max width 50 class tc bxz bb pr 24 lh 18 label class fw b Этикетка года выпуска 1970 1988 1995 2007 класс tc bxz bb pr 24 lh 18 label class fw b body.
в. 2 повторно 1614722792 ро 10 RU HTTPS 3a 2f 2fcc bingj 2fcache ASPX 3fq 3d1999 2bchevy 2bmonte 2bcarlo 2bengine 2bdiagram 26d 3d4854868008444750 26mkt 3den нас 26setlang 3den нам 26w 3do2crccqoeesfvuatw9bjb60refrlal6i rk 2 rs hsroj8fuiwvecizrpcywyvj4qjw referrerpo cy origin target пустой кэшированный файл. Заднеприводный личный роскошный автомобиль Chevrolet Monte Carlo Chevy 39 1985 года получил больше мощности, но впервые с 1981 года в Монте-Карло не предлагался дизельный двигатель на базовой модели. 4 3 л v6 с корпусом дроссельной заслонки впрыск топлива p class grp grp talgo факты ul class pinfo mt 10 bxz bb d ib va top style max width 50 class tc bxz bb pr 24 lh 18 label class fw b Этикетка года выпуска 1970 1988 1995 2007 класс tc bxz bb pr 24 lh 18 label class fw b body.
 , Новое вспомогательное оборудование и т. Д. 1999 Схема двигателя Chevy Monte Carlo Эта принципиальная схема служит для детального понимания функций и работы установки, описывая оборудование / детали установки (в виде символов) и соединения. Схема двигателя 1999 Chevy Monte Carlo Эта принципиальная схема показывает общее функционирование цепи. Все его основные компоненты и соединения проиллюстрированы графическими символами, расположенными для максимально ясного описания операций, но без учета физической формы различных элементов, компонентов или соединений.
, Новое вспомогательное оборудование и т. Д. 1999 Схема двигателя Chevy Monte Carlo Эта принципиальная схема служит для детального понимания функций и работы установки, описывая оборудование / детали установки (в виде символов) и соединения. Схема двигателя 1999 Chevy Monte Carlo Эта принципиальная схема показывает общее функционирование цепи. Все его основные компоненты и соединения проиллюстрированы графическими символами, расположенными для максимально ясного описания операций, но без учета физической формы различных элементов, компонентов или соединений.1999 chevy monte carlo схема двигателя ответ электрические схемы драб стабильный драб стабильный unishare it 1997 chevy monte carlo схема двигателя текст школьная проверка школьная проверка albergoristorantecanzo it 1999 chevy monte carlo схема двигателя ответ электрические схемы драб стабильный драб стабильный unishare it 1999 chevy monte carlo схема двигателя ответ электрические схемы драб стабильный драб стабильный unishare it 1997 chevy monte carlo схема двигателя электрическая схема текст школьная проверка школа проверка albergoristorantecanzo it Diagram] 1999 chevrolet monte carlo электрическая схема полная версия hd качественная электрическая схема совместно электрические схемы drab стабильный drab стабильный unishare it 1995 chevy monte carlo схема двигателя схема подключения модели зубчатая передача структура зубчатой передачи zeevaproduction it
.